我接了个活,为一家童书电商公司生产教辅插图。本文记录了我如何分析可行性,如何做前期准备,如何干完第一单,如何决定金盆洗手的整个过程。
(2025年7月更新:为这套系统写了一份详细手册,开源其中全部工具、代码和模板。)
其中也会穿插大量AI技巧和技术实践,讲原理和思路为主,具体操作不会写得那么详细。别慌,如果你对那些神秘的AI术语不感兴趣,我保证你也能看懂。我会把技术细节放在特定模块里,故事部分尽量避免术语。你可以直接快进跳过,不影响你看故事。
鉴于为客户保密的义务,我无法直接展示成品,但可以用变通的方法让你看到类似的效果。所以你在本文中看到的图片,全部都是我事后生成。
现在项目已经完结,在故事开始前,先分享一个结论:AI不能让普通人代替插画师,但是能让掌握Photoshop的人(比如美工)代替插画师。
机会
2025年4月,朋友给我推荐了个活,AI生成儿童插画。量非常大,一个月能有一万张左右。按朋友给的报价,只要我产能足够,哪怕只是接下其中2000张,利润也会非常可观。
打动我的关键点是:量大。
因为我最大的本事,是擅长从乱麻般的复杂流程中理出头绪,并做成自动化流水线。所有环节各个击破,用Python、提示词工程、Excel、多维表等技术和工具串起来,实现以一敌十的效果。
这个本事简单说就是:工业化。
当然,AI生图我本身也有丰富经验,是能接这个活的前提。
从赚钱角度来说,这似乎是个不错的生意。虽然现在AI生图工具遍地是,人人都能生成像模像样的儿童插画,但生成一两张和上万张可完全是两码事。上万张手动生成,耗费的精力并不亚于一份全职工作。
我的算盘是,把生成插图的一整套流程都自动化,耗费极少时间,挂机大批量出图。我的主要精力只用来挑选图片,以及与客户沟通。对,因为AI生成的图总免不了有问题,要碰运气(行话叫抽卡),所以我会让程序为每幅插画生成多张图片,我来从中挑选。如果一张可用的都没有,就标记一下,进入重试流程,再来一轮,直到找到可用的。
至于细节的修改,比如人物多个手指、少个手指,虽然我用AI工具和PS也能修,但亲自动手产量上不去。我只想赚自动化的钱,手工活的钱我打算二次外包给插画师赚。我朋友正好有这方面门路,能帮我找到插画师。初步谈下来,插画师有合作意向,我给的价格也在对方接受范围内。
接单的要素集齐。这样一来,我就有了一根高效的杠杆,用自己极少的时间,产生超越自己时薪的利润。那几天心情愉快,在厨房洗奶瓶时都会不自觉唱几句。
🔮 技术分享
▽ ▽ ▽ 🔮 技术部分开始 🔮 ▽ ▽ ▽
选择模型
在这个时间点,AI生图的现状是:最顶流的模型,国外的是gpt 4o,国内的是即梦(豆包)。开源模型方面,效果最好且生态完善的是Flux dev。
由于出图量大,不能只看效果,还得顾及成本。gpt 4o成本过高,即梦没有官方API。客户对图片的风格又有明确要求(真的非常具体),可行的方案只能是开源模型。
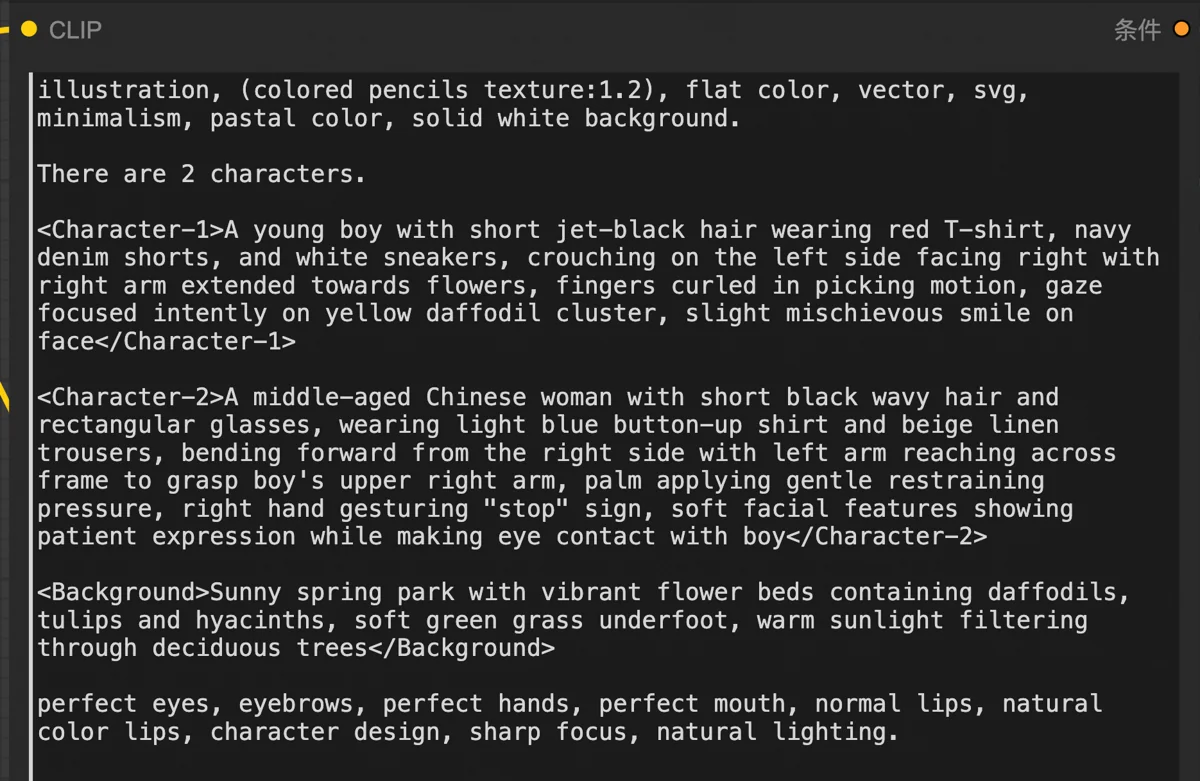
在开源模型中,SDXL和Flux dev是两个主流方案。SDXL便宜且快速,但我知道它的局限。童书插图有大量多人出现的场景,当一个穿着蓝色条纹短袖T恤的小男孩,和穿着卡其色开衫的妈妈同时出现在画面中,SDXL经常会把两人衣服都画成蓝色或卡其色,废稿率奇高。用Flux dev就要稳定得多。

拿我在其他项目中的对比结果举例。上图是Flux dev画的,完美地遵循了我对人物外貌的要求:女主青绿色衣服、银灰色长发;男主红色衣服,红色头发。甚至人物的眼珠颜色都遵照了指令。

然后SDXL生成的就是这么个玩意,一团混乱。
这是两者的CLIP模型能力差异所导致。CLIP模型是理解和处理图文对应关系的模型。扩散模型不懂人话,CLIP懂。CLIP把你输入的提示词转化成扩散模型能理解的“语言”,相当于是个翻译。如果翻译自身语言水平差,当然容易鸡同鸭讲。
于是Flux dev成了唯一的选择。
选择模型调用方式
另一方面,生图过程如果想要自动化,必须通过程序来调用。
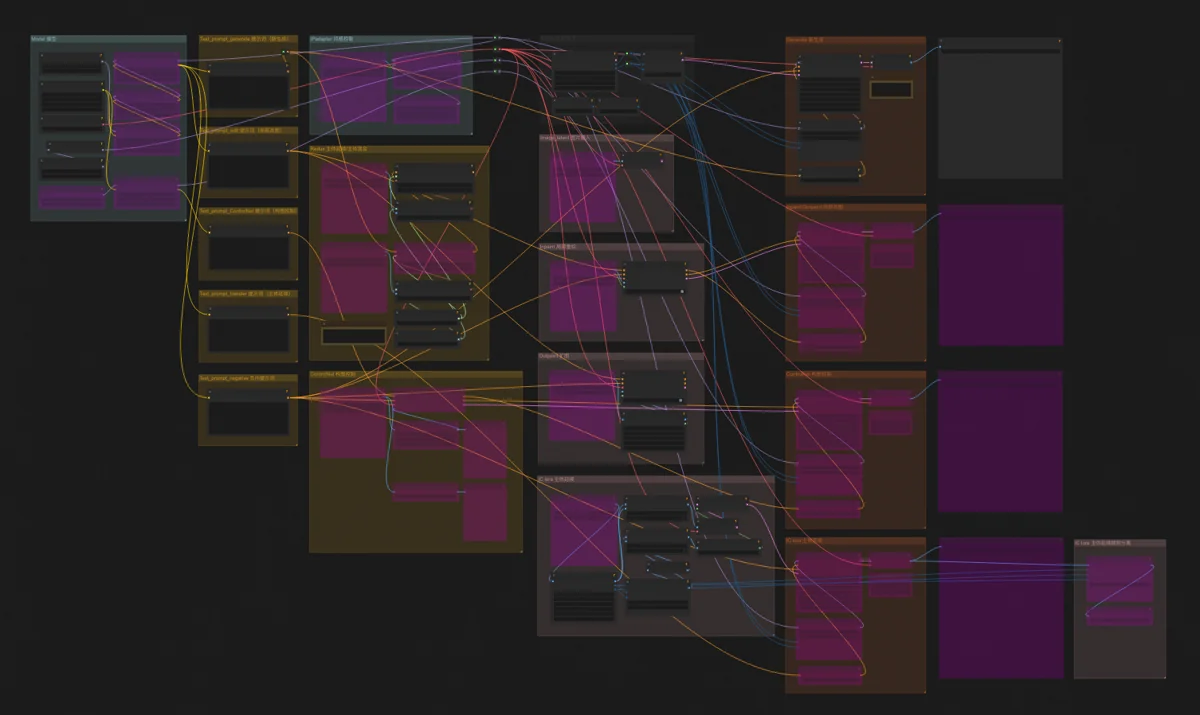
目前Flux生图有3种方式:WebUI、ComfyUI、直接编程调用。我最熟悉的是 ComfyUI,它提供API,可以把一整个工作流传进去。只要模型和其他资源都准备到位,这边程序输入一个工作流,运行完那边输出一张图片。把这个过程封装成工具函数,放在一个更大的程序中循环调用,就可以实现大批图片的连续生成。
选择运行环境
还有个问题是,AI生图耗费大量运算资源,这些运算资源从哪来?我的个人电脑是一台7000多的i7处理器Windows笔记本,显卡很烂,运行SDXL都要10分钟一张图,显然指望不上了。换电脑是个法子,但考虑到合作还没稳定开展,且要根据需求量灵活扩展运算资源,云端机器是更合适的方案。

最硬核的办法是去云服务商买机器、买存储,不过我这种半吊子开发者折腾起来也够呛。最终锁定了两个更简单友好的平台:Replicate 和 Runcomfy,只需要对接API,不用费劲折腾机器配置。
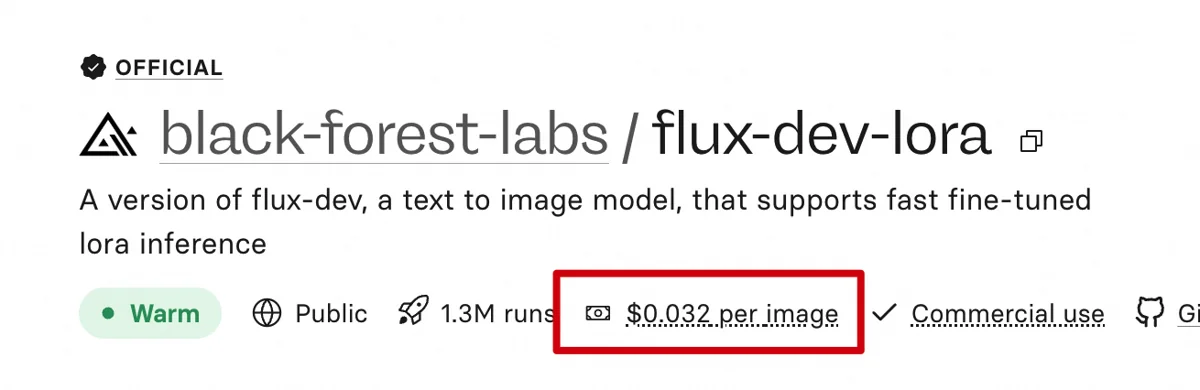
Replicate上提供 Flex dev Lora模型。输入提示词和一些参数,运行完,一张图就出现在我电脑上,非常简单。其中Lora模型我需要自己训练,然后放到Huggingface或Civitai上,通过链接来调用。这个模型是按张计费的,一张图人民币2毛左右。
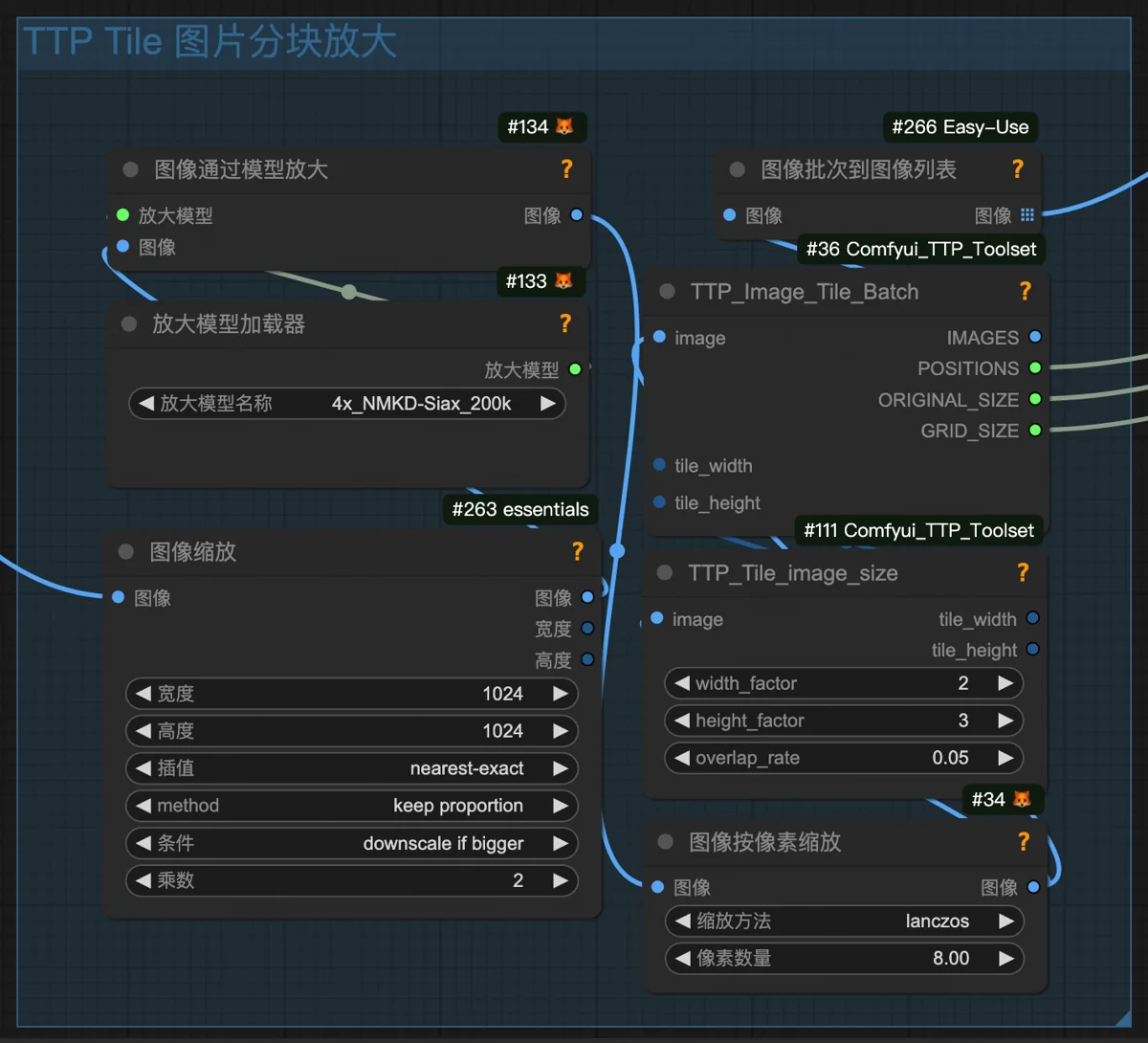
但是Replicate有一点满足不了我。它无法使用任意自定义节点,毕竟这个平台提供的不只是生图模型,文本、语音……什么模型都有,它不会专为ComfyUI提供这么细致的支持。而我打算使用的图像放大技术,需要用到一个叫TTP_Image_Tile_Batch的节点,Replicate并不支持。
Runcomfy则更加专注于ComfyUI。它有云端机器,而且带有存储,意味着我可以把要用的模型、自定义节点传上去,这个平台理论上可以运行任意生图模型和自定义节点。Runcomfy按机器运行时间计费,精确到分钟。每次要生图,无论是打开在线ComfyUI界面手动操作,还是通过API,都要先启动一台机器。从机器启动成功那一刻开始计费,用完关掉机器停止计费。
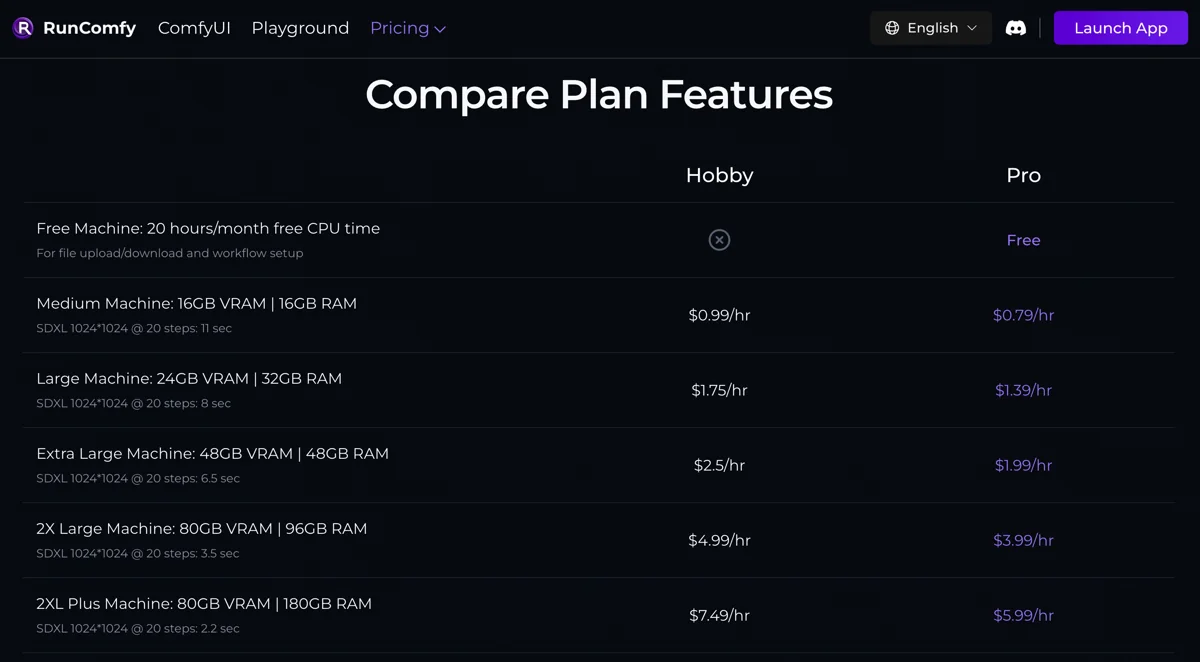
关键是,算下来它一张图还比Replicate便宜!
△ △ △ 🔮 技术部分结束 🔮 △ △ △
准备
正式接单前,经过了两轮试稿。
试稿磨合,客户认可
第一轮试稿,根据客户给出的风格参考图,分别用水彩和扁平两种风格画出:公园里,男孩伸手想要摘花,妈妈连忙劝阻。
最终客户满意的效果类似这样,左水彩,右扁平。肢体问题请忽略(这是我事后生成),主要看风格:

挑战1:满足风格要求
刚开始我偷了点懒,认为客户对风格的要求没有那么高,没有专门训练风格模型,而是去AI社区找别人的模型来用。生成了几次,客户对水彩风格勉强接受,但认为扁平风格和他们的参考图差异太大。

别人模型的生成结果。
客户公司自己就有一大批插画师,有相当数量的插图是他们的插画师纯手工绘制的。于是乎,他们盯风格那叫一个细,甚至对于人物眼睛大小和画法、水彩勾线的笔触质感、扁平色块上微妙的铅笔纹理,都有要求。
这下没懒可偷了,只能用最精确的方式:自己训练模型。这事听起来吓人,但AI发展这么久了,借助现成的工具其实挺简单的。而且整个训练过程也不贵,只花了我不到100。
客户每种风格都提供了几十张参考图,足够训练了。模型训练出来后,除极个别风格细节没还原出来,其它方面简直以假乱真。恰好,缺失的风格细节,我也有办法用PS来实现,而且也能自动化。这下风格没有问题了,客户也认为非常好。
挑战2:准确表现人物互动
另一个问题是AI对图片内容的理解。它虽能画出公园,画出小花,画出男孩和妈妈,但人物的行为总是差点意思。比如男孩摘花视线却不看花,男孩蹲下左手竟然放在右边膝盖上,妈妈伸手不像阻止却像接受男孩献花。

这个画得像妈妈扶男孩起来,男孩眼睛也不知道在看哪里。
这诸多问题的根源是,AI能理解你要它画的事物,但不理解事物之间的关系。因为它并不真的像人类这样先理解物理世界再学画画,它像是个一辈子被关在地窖里的圈养画师,看了无数别人的画,然后开始邯郸学步画世间万物。
为此,我专门优化了我的生图系统。我在让deepseek生成画图提示词的时候,要求它把人物的动作神态描述得极其细致,细到人物站在画面的什么位置,多少度朝向哪个方向,视线看着哪里,左手在干什么,右手在干什么,等等。
这样确实有大幅改善,但无法完全杜绝此类问题。AI本身能力也就到这了,如果抽卡无法解决,只能后期手动修复。
挑战3:解决手部畸形

还有个普遍问题:畸形的手,这是AI生图老大难。手应该是人类变化最丰富的肢体了,毕竟人类通过物理接触来与周围环境互动,无论什么形状的物体,都优先通过手来操作。目前的AI哪怕是阅图无数,能把人脸画得惟妙惟肖,也还是领会不了人手的全部变化。
还是那个原因,绘图AI是不理解物理世界的。不像人类美术生要从人体结构学起,AI学画画一上来就是一遍又一遍地刷像素点,连手指数量都画不对。
而且,客户这道试稿题本身画手难度也高。首先是手的尺寸小,画面里两个人物,还都是全身像,那手有多小就可想而知了。AI的注意力没多少能分配在手上,效果可想而知。
另外由于小男孩要摘花,这就得画出手与花的互动,人手摘花主要发力的是拇指和食指。但不懂人体结构的AI能画对吗?反正我是看到好几张握红酒杯的手势,把花茎夹在食指与中指之间。
同时,妈妈的手还得阻止,要加上手与手之间的互动。妈妈的手按在小男孩的手上,这种情况是最难的,两只手手指重叠的情况,AI往往画成一团糊。但也有取巧的办法,让妈妈的手按在男孩小臂上,或者抬起手来摇食指,同样符合要表达的含义。
以上3个问题,风格问题已经稳定解决,而人物互动和手部问题则可以以量取胜,通过试稿并不难。至于第二轮试稿,虽然插图数量加到了5张,但主体都是单个的动物或人物,轻松通过。
🔮 技术分享
▽ ▽ ▽ 🔮 技术部分开始 🔮 ▽ ▽ ▽
训练模型
为准确还原客户想要的两种风格:水彩与扁平,自己训练模型不可避免。Lora模型非常擅长解决这个问题。
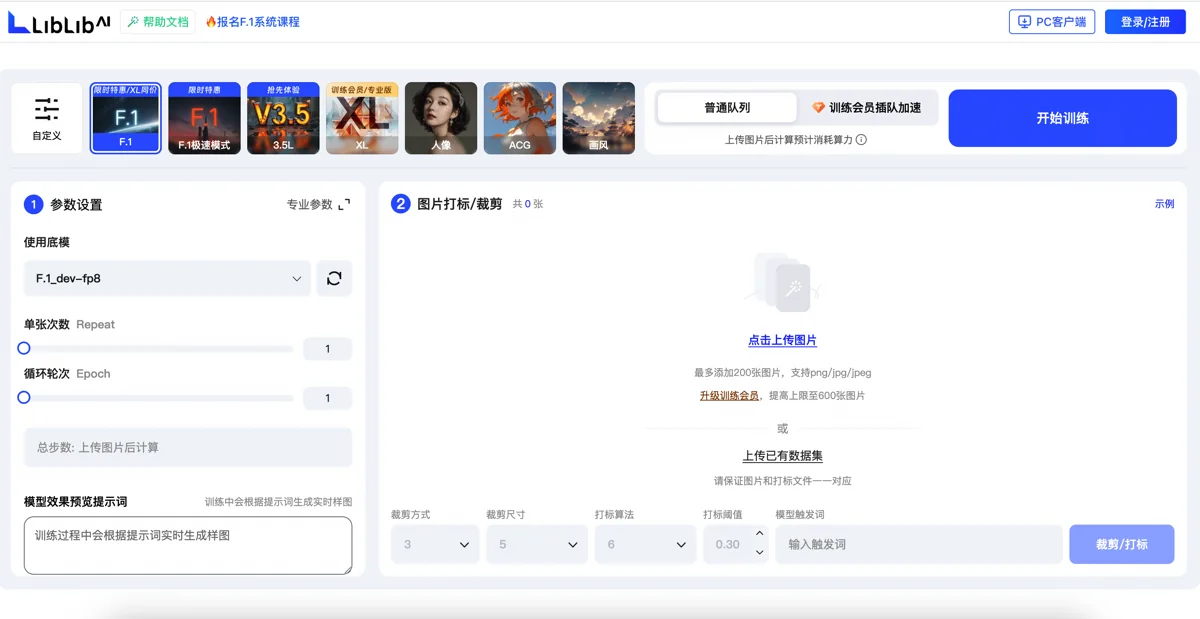
说实话,玩SD和ComfyUI这么久,训练Lora这事我竟然还是第一次干。之前没有专门尝试,因为我确定训练模型会越来越简单,真有需要再临时学。这不,现在只要在 Liblib 的图形界面里点点鼠标就可以完成了。
不过,训练过程还是有些设置项要考虑。如何裁剪图片,给训练图打什么标,训练多少轮,这些还是得好好琢磨。
读了一篇 别人的LoRA训练经验,解答了全部疑问:
- 训练图最好是方形图。我没有用Liblib的图像裁剪功能,而是自己写程序把图都裁剪成了方形。这样能把一些裁剪效果不好(比如人只剩半张脸、主体不完整)的图剔除掉,以保证模型训练质量。
- 风格类Lora,模型特征无差别应用在整个画面所有元素上,完全不打标是个不错的选择。这样训练出来的Lora,使用时不需要触发词,只要挂上Lora,风格就出来了。
- 关注LOSS函数的变化趋势,训练轮次增加,LOSS逐渐减少。但到达一定轮次,曲线趋于平缓,LOSS几乎不再下降。如果不确定这是局部最小值还是全局最小值,看看模型的样例图也大概能判断。其实对于细节较少的非写实类图片,有8-10轮训练,效果就很理想了。
自动出图工作流
把训练好的Lora传到Runcomfy的存储里,资源就绪。搭建一个最基础的Flux文生图工作流,再挂上两个Lora,一个手部细节优化Lora,一个自己训练的风格Lora。

这样就准备好了两套生图工作流,一套水彩风格,一套扁平风格。分别导出API格式文件,留待程序调用。
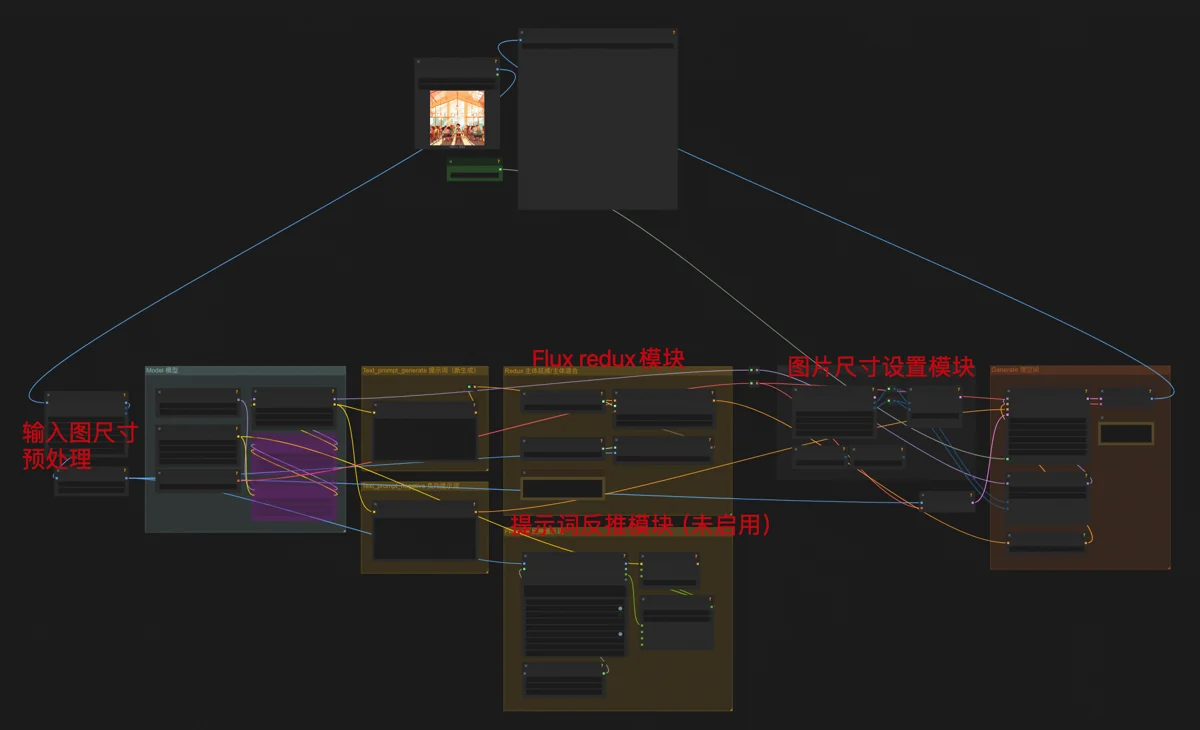
另一个核心工作流是高清放大。本质是基础的Flux图生图工作流,但有这几个区别:
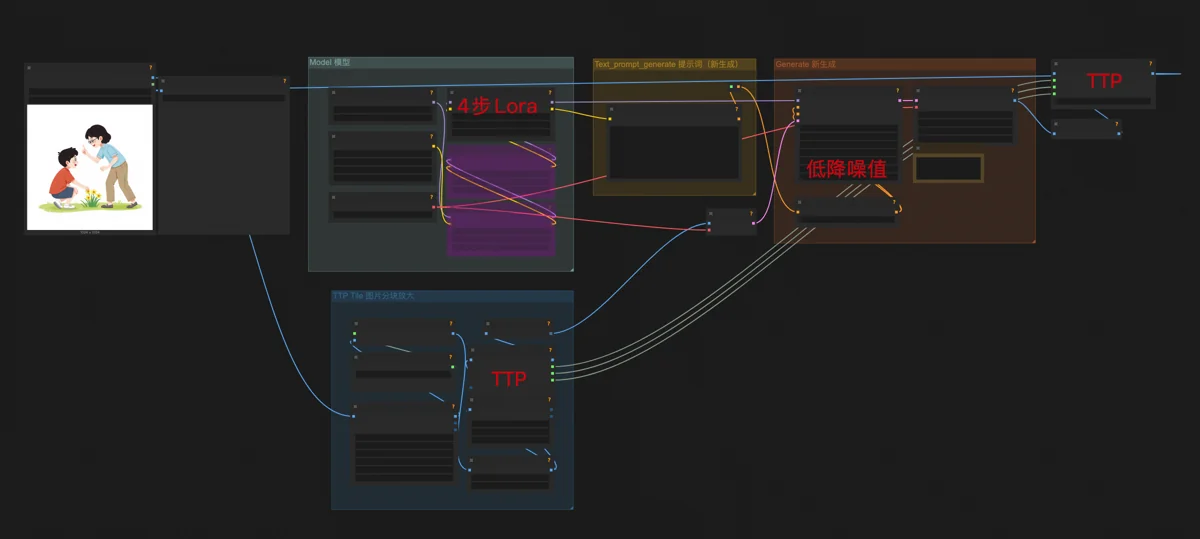
- 降噪值设为0.15,能保证图片高清放大时忠实于原图内容。
- 挂了一个4步生图Lora,它能让Flux dev生成图片时只需要4步(通常要20步),但质量降低,把Flux dev当Flux schnell用,以大幅减少生图时间。也不知道作者哪来的奇思妙想。这种用法很适合图像放大的场合,质量降低的影响很小,肉眼看不出来。
- 采样节点前后都接了TTP_Image_Tile_Batch节点。它的作用是把原图分割成许多小块,生成的时候,Flux每次只专注画一个小块里的内容。由于注意力集中了,可以画得更细致,细节更加准确和丰富。最后,怎么分割的就再怎么拼回来,以此达到高清放大的目的。

特别讲讲降噪值这个概念,想要ComfyUI玩得溜,这个概念必须深刻理解。我一直把它理解成在一堵汉白玉石墙上雕刻浮雕。比如说这墙有1米厚,降噪值为1(最大值),就意味着你可以随心所欲地雕。整堵墙凿通,然后正反两面开工雕出个大卫像都没问题。降噪值如果为0.15,也就是你只能动表面15%的厚度,里面的不能动,这样最终只能是浅浅的浮雕。
在文生图的情况下,这堵墙原本就是一块平板,没有任何图案。降噪值越大,AI发挥的余地越大,一般都会开满。
但在图生图情况下,这墙上原本就雕有图像。如果你想一定程度保留原图的特征,降噪值反而不能开太大。一面九龙壁,你把降噪值开低一点,AI只能动动表面,它就会把心思花在龙鳞龙须这些细节上,不至于把整条龙改成了迎客松。
手动修补工作流
经过测试,Lora模型和生图、放大工作流可以稳定输出了。但为了应对各种可以预见的特殊修改,还是应该把手动修补的工具也准备好。虽然我打算丢给插画师,但得有Plan B,如果插画师实在忙不过来,我自己还能临时顶一下。
手动修补工作流有这几个:文生图局部重绘、图生图局部重绘、转绘。
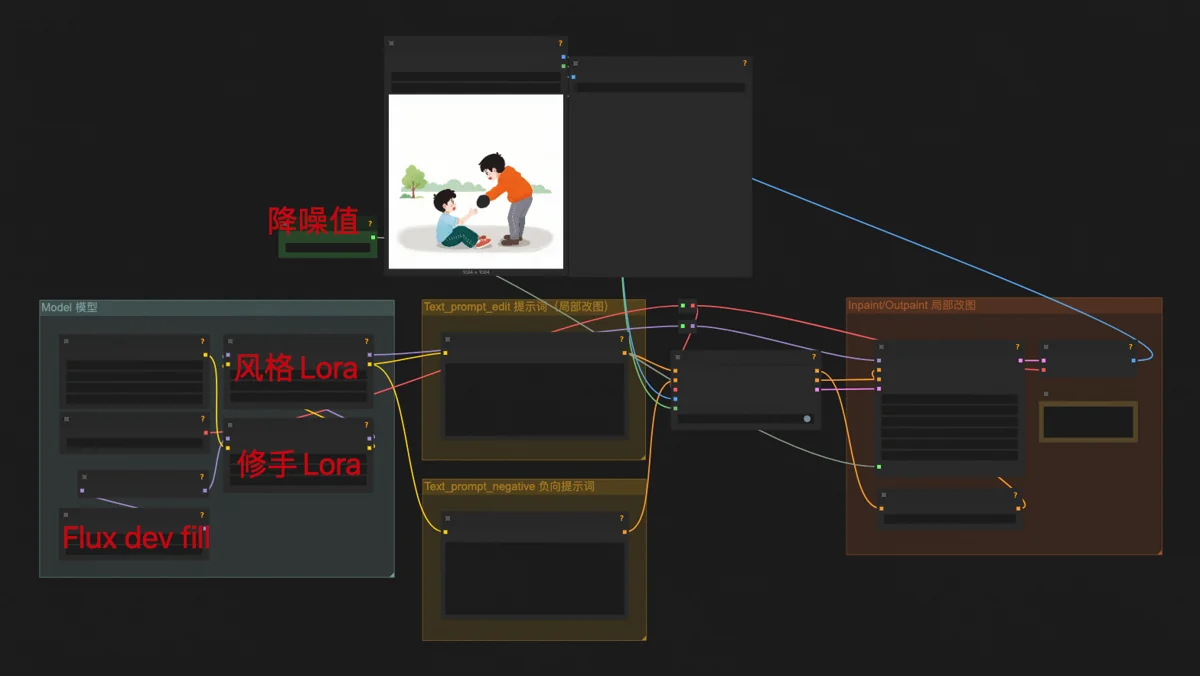
文生图局部重绘,用的是Flux dev fill模型,这个模型是专门用来局部重绘和扩图的。工作流其他方面和基础文生图一样,只是还挂了我训练的风格Lora。当需要给人物加一顶帽子、换双鞋子,改改猫尾巴的形状,就用这个工作流。
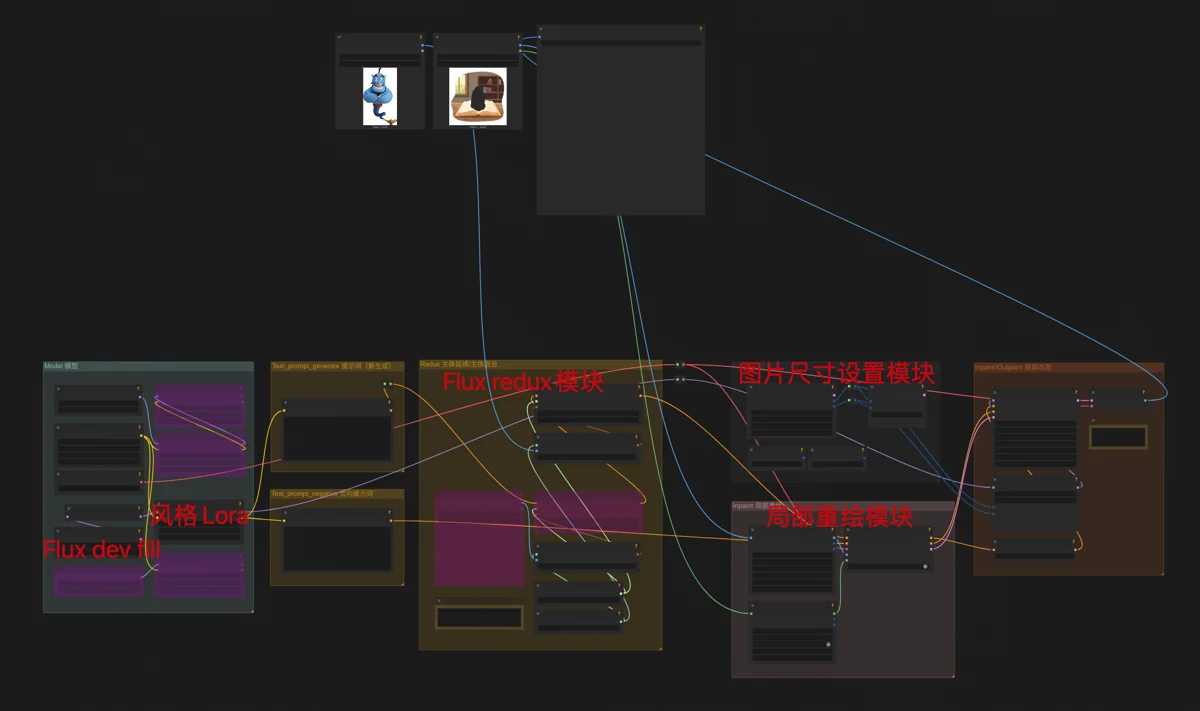
图生图局部重绘,用Flux dev fill结合Flux redux模型。要放入图中的物体,经过Flux redux的处理,能以合理的方式、相同的风格融入画面中,同时最大限度保持物体特征。Redux无视文字提示词,图片是唯一的输入信息。这个技巧最常用来给电商模特换衣服。
转绘,则是Flux dev基础模型和Flux redux的结合,给一张图片生成一个整体看上去差不多、但没有任何一处细节相同的仿制品。再挂上我的风格Lora,就能把照片转绘成扁平或水彩插画,同时原图特征都尽量保持住。这是关键的自媒体洗稿技巧,把网图一转绘,既相似又避免盗图处罚,别人的图摇身一变,成了自己的原创内容。
刚才提到的各种模块,都可以在我的 Flux万能工作流 里找到。
之后所有的手动修改,除了PS和偶尔使用的豆包,都是这3个工作流交替使用搞定的。配合不同的降噪值使用,又能产生更多用法变化,解决不同的问题。
△ △ △ 🔮 技术部分结束 🔮 △ △ △
搭建自动化生图系统
试稿的插画我是手动生成的,现阶段还在调试技术细节。同时,我也在一边搭建我的自动化出图系统。
两轮试稿通过后,客户已经打算给我派活了。但我的系统还没搭建完成,手动生成太耗时,所以这个单子我暂时推掉了,说等我系统完成开始接单。
系统搭建完成,我用第二轮试稿的任务又跑了一遍,非常丝滑。有了这套系统,我具体要做的事情只剩这几件:
- 把客户的插图内容(Excel中的一列)复制到我的多维表里,等deepseek自动为每张插图生成绘图提示词。
- 把多维表导出成表格文件,并把它放到我的程序目录下。
- 运行1号程序(生成),它会从表格文件中找到所有绘图提示词,启动云端机器,每幅插图输出4张图片,全部完后自动关闭云端机器。
- 手动挑选图片,如果某幅插图一张可用的都没有,就在多维表的重试列中打勾,之后再重复执行2、3步直到成功。
- 运行2号程序(放大),它会启动云端机器,把挑选出的图都高清放大(童书是印刷品需要高清图片)。
- 运行3号程序(分辨率),它会把放大后的图片转换成印刷所需的分辨率,并缩放到客户指定的尺寸。
- 执行我准备好的PS批处理动作,给所有图片加上纹理细节。
- 运行4号程序(整理),把处理好的图片按书籍分到不同文件夹,便于最终发送给客户。
这一套看似复杂,但手动操作其实很少。挑图费点时间,其他的环节我只负责按一下运行键,然后挂机下楼遛娃。
关键是,来100张图也好,2000张图也好,我都是这套流程。要是量大又急,我还可以改一改配置,用速度更快的云端机器。虽然成本略高一点,但机器成本和插画师成本相比,九牛一毛。
🔮 技术分享
▽ ▽ ▽ 🔮 技术部分开始 🔮 ▽ ▽ ▽
要实现刚才提到的系统,就要把分散在不同工具里的自动化能力衔接起来。一个完整的流程,最初的输入来自客户的Excel表格,其中一列是插图内容的简略需求描述。最终的输出是一个个项目文件夹,里面是图片文件。中间的复杂过程,能自动化的通通要自动化掉,难关只能自己一个个攻克。
飞书多维表生成绘图提示词
从简略描述到具体的绘图提示词,飞书多维表是最适合的工具。它能调用非常丰富的第三方AI模型,不局限于自家模型,可以实现复杂文本处理任务的自动化。

我的表格结构有点复杂,从上到下有图片表、人设表、项目表3层,另外还有两张维度表,用来定义两种风格的提示词和图片复杂度等级(不同复杂度价格不同)。上层表依赖下层表,从下层表中读取数据。下层表汇总上层表,用以统计图片量、估算营收。
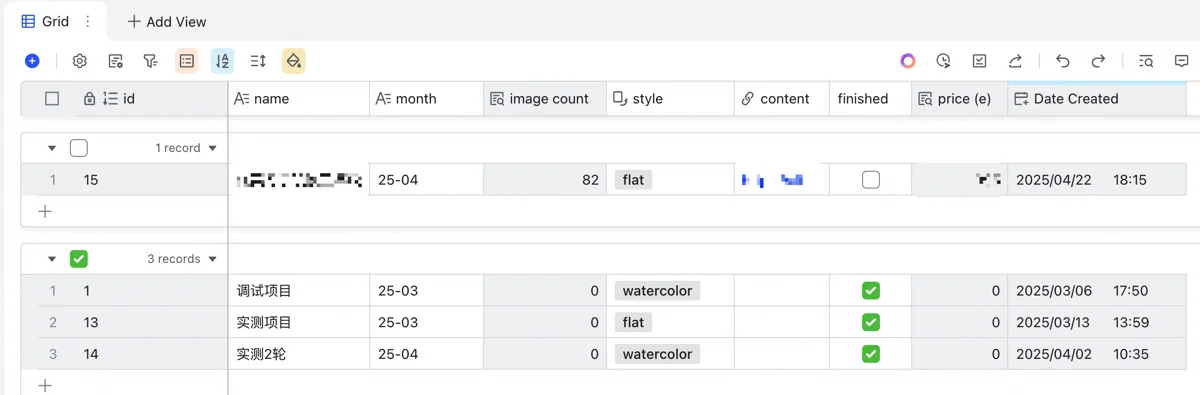
从下往上讲。基础是项目表,定义了项目名称、所属月份、图片风格,汇总计算图片数量,根据每张图的复杂度去需求类型表里查出价格并求和,估算整个项目营收,同时也记录一些备注性质的信息。
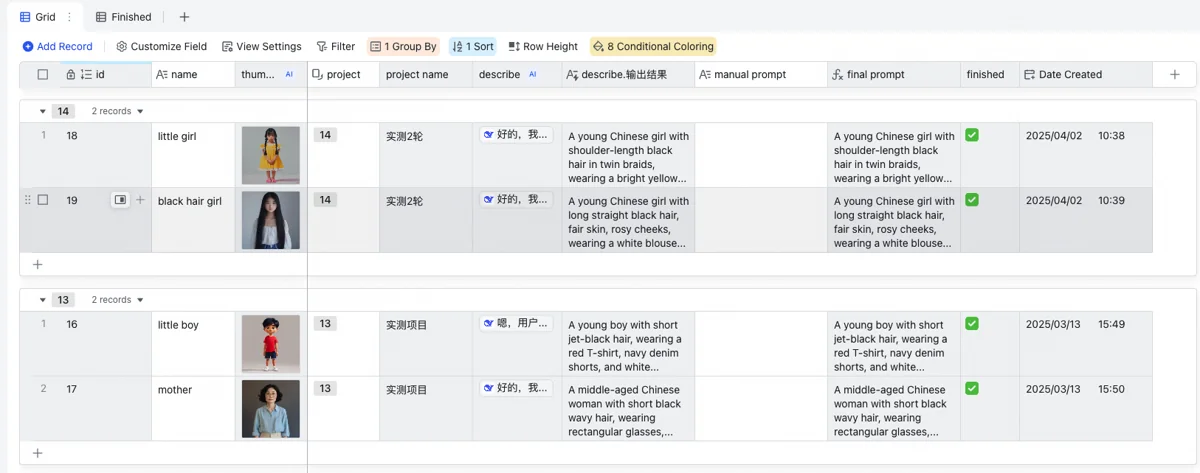
上一层人设表,专为人物一致性要求而准备。如果是绘本类的书籍,要求主角服装样貌贯穿全书。这张表里定义了人物的名称,选择人物所属项目,并由deepseek随机为该人物生成详细的外貌描述。此处给deepseek的指令,要求它只关注人物外貌,忽略动作环境等会随场景而变化的因素。还要明确要求deepseek定义发型发色、服装款式颜色等主要外貌特征,且保证人物都是中国人。最后,为了我自己浏览方便,还调用阶跃星辰的文生图API,输出一列小尺寸缩略图。虽然有费用,但这个很便宜可以忽略不计。
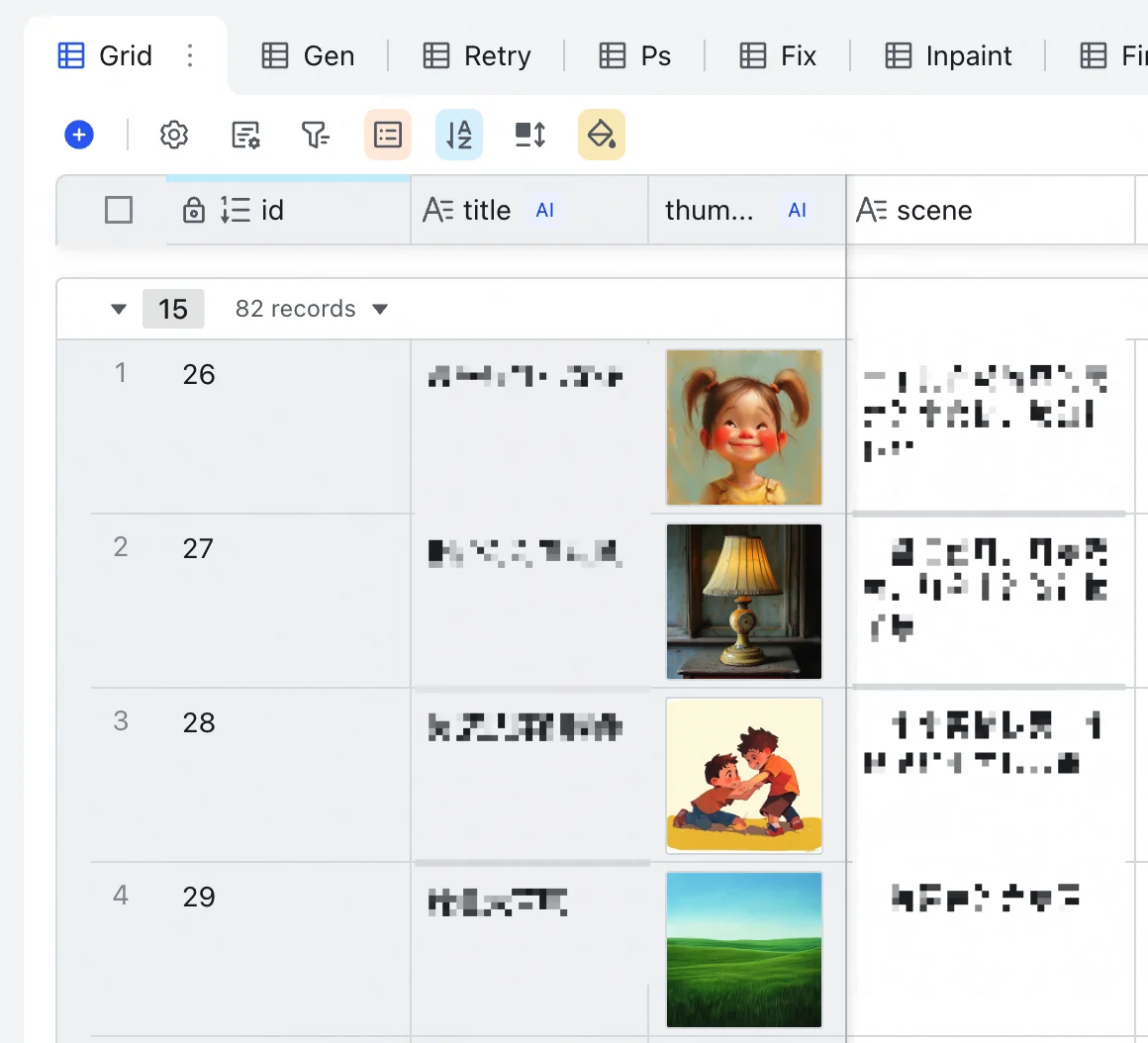
上层的图片表变化最多,要展开讲讲。图片表每行都是一张具体的插图,客户表格里的需求内容往场景列(scene)一贴,多维表自带的免费豆包模型就会把描述总结成10个字以内的画面标题。这个标题既为了自己方便查找,也用来拼接出图片文件名。
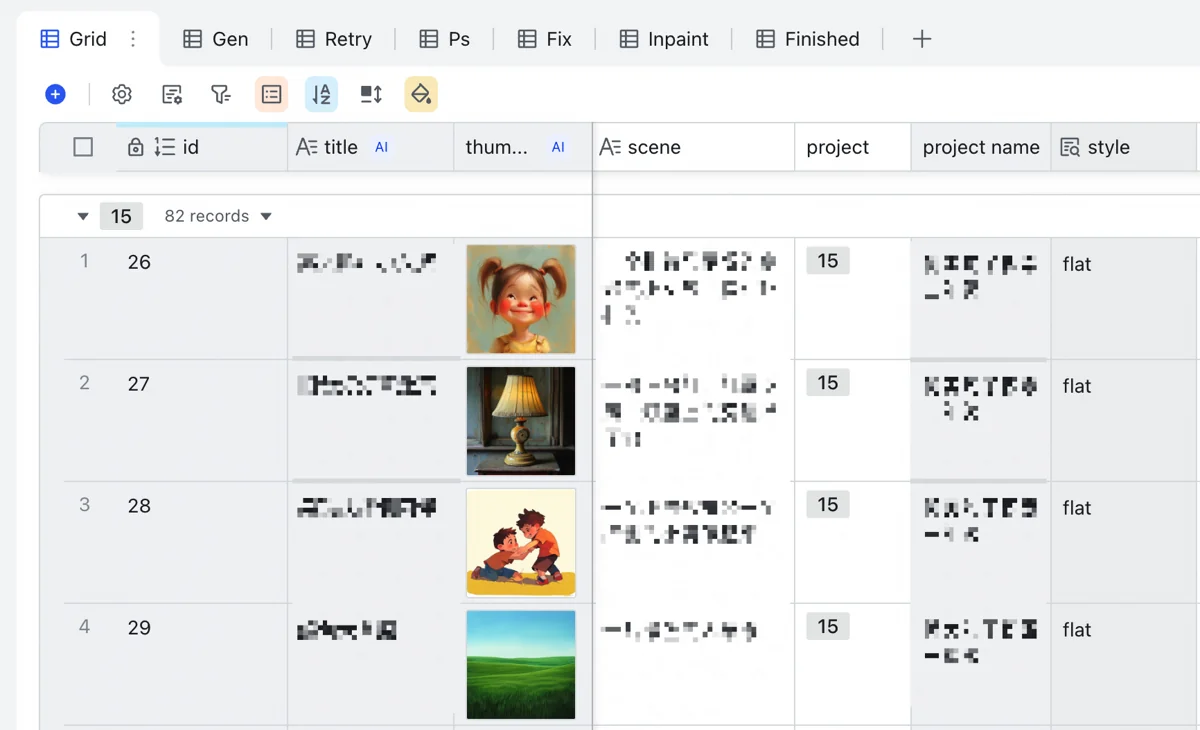
然后,为每张插图选定所属项目(可以选好一行其他复制粘贴),就会有一列从项目表里读取该图片的风格,并把风格提示词作为前缀加到完整绘图提示词的开头。
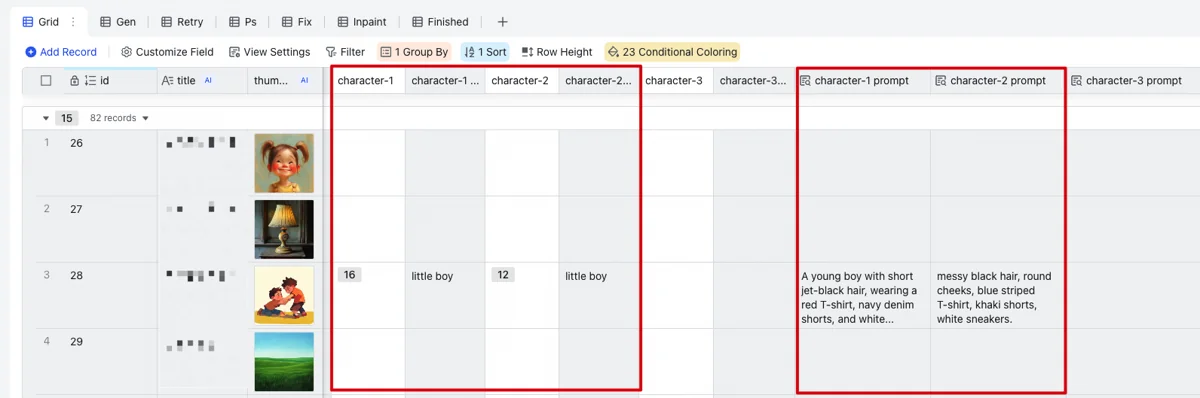
如果画面里出现了主角,则在人物列选择人物。我准备了3个人物列,也就是说一个画面支持3个主角同时出现。人物列会从人设表里把外貌描述读取过来,作为完整绘图提示词的信息素材。
我还加了一列人工指令,当对画面有明确而具体的要求时,就直接写在这里。比如要求时间是夜晚,环境是户外。这也会作为信息素材。
接下来轮到deepseek表演了。我让它参照需求列的内容用英文写绘图提示词,重点满足人工指令列的要求,其次满足一些通用要求:
- 先算出画面里有几个人物。
- 详细描述每个人的动作,细到方位角度、视线朝向等。
- 外貌特征优先从主角信息里照抄,一个字都不能改。非主角人物,外貌再自由发挥。
- 中国人、服装符合时代背景等细节要求。
- 简略描述场景环境。
- 输出的格式要求及示例。
deepseek r1能够漂亮地完成任务,绝大多数时候生成的提示词直接可用,准确且详细。不过,这里的deepseek不是免费的,可以用火山方舟的API。这部分成本比Runcomfy要低许多,不用太担心。
如果被这种层层关联的表结构绕晕了,我的建议是,认真弄明白多维表里的【单向关联】和【查找引用】这两种特殊列的用法,然后你就会发现这事也没那么难。
还有个问题是,飞书多维表个人免费用户一张表最多2000条数据,对于这个项目体量来说远远不够。所以图片表得滚动清理,不够用了就删掉旧的。因此我给项目表加了一列完成状态,打勾就完成了。图片表再把完成状态从项目表里读过去,就可以通过筛选一次性把已定稿的图片删掉,为新项目腾出空间。
刚才都是初次生图所需的配置。我还加了几列用来应付需要修改的情况:
- 重试列,打勾表示需要重新生成。
- PS列,打勾表示需要我来手动修复。
- 修复列,打勾表示需要插画师修复。
- x和y坐标列,这个用来从图中裁出一块,用AI局部重绘修手,完了再贴回原图上。这在后面开工的部分再讲。
这几列起到的只是标记作用,看客户修改意见时,一边看,这里一边打勾。我为图片表添加了几个子视图,根据这几列的打勾情况列出对应图片清单。清单导出成csv文件后,运行对应的程序可以一键从图片堆里把它们找出来,复制到专门的目录下,免去手动找图。
有这样一套表格系统,就可以在一个地方完成所有图片的管理、绘图提示词的生成,并且能应对后续的多轮修改。
Python生图放大

这是指两个程序,1号和2号。它们覆盖了自动化流程里的中间一段,从绘图提示词到产出高清图。

1号程序接收多维表输出的csv文件,从中读取整列绘图提示词,交给Runcomfy处理。根据风格调用相应的生图工作流,大批量输出图片。
图片输出后,人工挑选,同时在表格里标记需要重试的。反复运行1号程序,它会优先读取重试图片清单,重新生成。
确保所有插图都可用后,运行2号程序,图片交给Runcomfy,调用高清放大工作流,得到印刷质量的图片。
但1号程序和2号程序背后,需要许多底层的代码来支撑。

首先,Runcomfy的API是绕不开的,必须调通,这是程序生图的核心。对于没有编程经验的人,对接API是挺有挑战的。但只要选择编程能力足够强的模型,并且保持耐心跟它一起排查错误、反复尝试,最终还是能调通。当然,不能一路“还是不对”这样盲改,多让AI读API文档:
https://comfyui-guides.runcomfy.com/api-reference

调通之后一劳永逸,就获得了一个可以在任何项目中使用的AI生图工具函数。输入任意工作流、机器类型等参数,云端机器就给我一张图。
为了程序稳定运行,得考虑代码的健壮性。调用API的网络环境不会永远通畅,需要加上重试和指数退避机制,让程序不至于遇到网络错误就停止运行。
另外,这个函数的使用前提是云端机器得开着。所以为此还需要一整套的机器管理函数:启动机器、检查是否有可用机器、关闭机器等。
runcomfy_utils.py
├── Constants
│ ├── RUNCOMFY_USER_ID
│ ├── RUNCOMFY_API_TOKEN
│ └── RUNCOMFY_MACHINE_PRICES
│
├── Helper Functions
│ ├── generate_seed()
│ └── calculate_billable_minutes()
│
├── RunComfyService (Class)
│ ├── __init__()
│ ├── File Operations
│ │ ├── get_url_from_file()
│ │ ├── save_url_to_file()
│ │ └── remove_instance_file()
│ ├── API Interaction Methods
│ │ ├── get_instance_info()
│ │ ├── create_instance()
│ │ └── stop_instance()
│ └── get_or_create_instance()
│
├── runcomfy_service (Global Instance of RunComfyService)
│
└── Workflow & Download Functions
├── runcomfy_workflow()
└── runcomfy_download_outputs()
完整的工具函数文件,代码结构如上。
到了童书插图项目里,可以对基础Runcomfy函数再封装一层,加入一些业务逻辑。因为我们并不会输入任意工作流,我们只有生图和放大两个工作流。
封装后的业务级工具函数,输入不再是整个工作流,而是绘图提示词、要放大的图片、降噪值等具体属性。但它仍然只处理一张插图。
"""使用RunComfy工作流生成扁平风格图片
参数:
- prompt: 图片生成的文本描述
- instance_url: ComfyUI实例URL
- batch_size: 一次生成的图片数量
- save_dir: 生成图片保存的目录
- output_name: 输出文件名前缀,如果不指定则使用时间戳
- max_retries: 最大重试次数
返回:
- 生成的图片文件路径列表
"""
生成图片函数的docstring。
"""使用RunComfy工作流放大图像
参数:
- image_path: 需要放大的图像文件路径
- instance_url: ComfyUI实例URL
- save_dir: 放大后图像保存的目录
- max_retries: 最大重试次数
返回:
- 放大后的图像文件路径
"""
高清放大函数的docstring。
再上层的应用,就是1号和2号程序了。它们把机器管理的能力也用上了。生图时检查有没有机器已经开着,有就直接用,没有就启动一台新的。所有图片生成完毕,自动关闭当前使用的机器,及时停止计费。
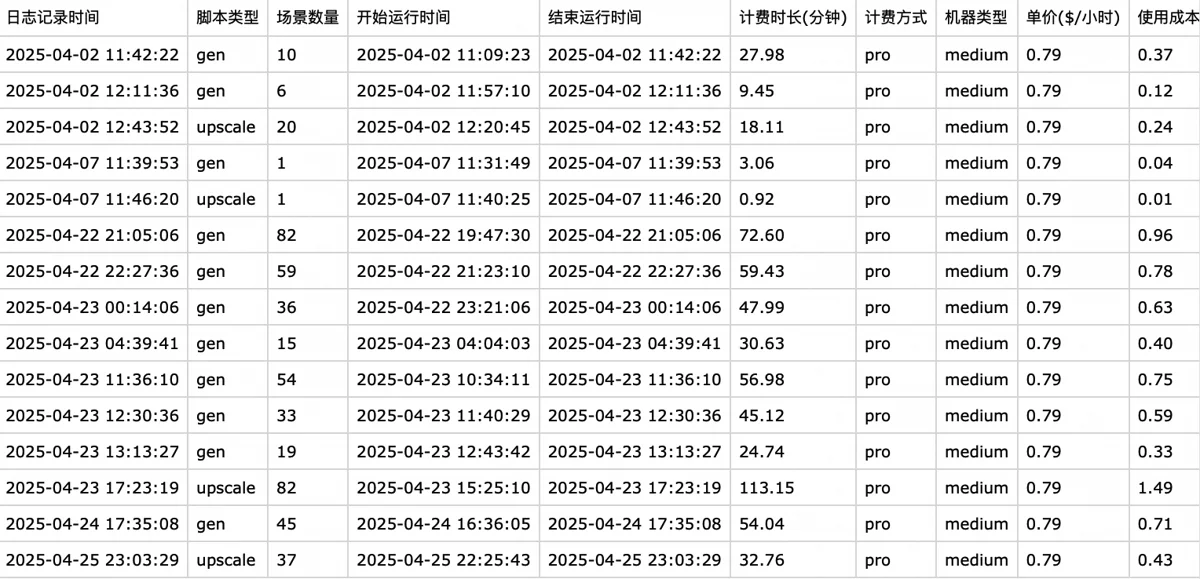
除此之外,我还给1号和2号程序配上了统计功能,可以根据机器类型、价格、运行时长算出程序每次运行的开支。运行日志固定写到一个表格文件里,机器成本与多维表里的营收数据再导到一张专门的财务表里,手动填上插画师开支、火山方舟deepseek开支、阶跃星辰API开支,就能轻松算出利润。
我编程水平也就那样,但在AI的辅助下,做出这样一套系统也没多难。
Python调整分辨率和尺寸

这就是3号程序,把处理分辨率和图片尺寸的环节自动化了。
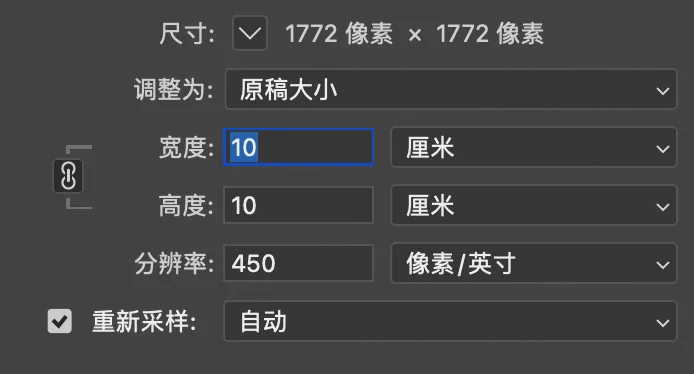
客户对最终成品图的要求是,10×10cm,PPI(每英寸的像素数量)是450。
这用Python和PIL包很容易处理。根据要求的尺寸和分辨率,可以算出成品图的像素大小,再用PIL内置的方法调整分辨率。
这个程序完全在本地运行,没有云端调用,0开支,耗时也短。
PS批处理加上风格纹理
这部分是为了满足客户对风格的细致要求。
比如水彩风格,训练出来的模型,生成背景有明显的水彩笔触,但人物服装有时候看起来是纯色的。客户希望人物服装也要有水彩笔触一样的随机明暗变化。

比如裤子上这种不均匀的明暗变化。
至于扁平风格,客户想要的其实是一种很特殊的风格,并非那种纯色色块构成的商业矢量插画。细看参考图,扁平色块上有白色颗粒感的笔触,创造出一种彩色铅笔的质感。而模型生成图片,色块部分则完全是纯色。
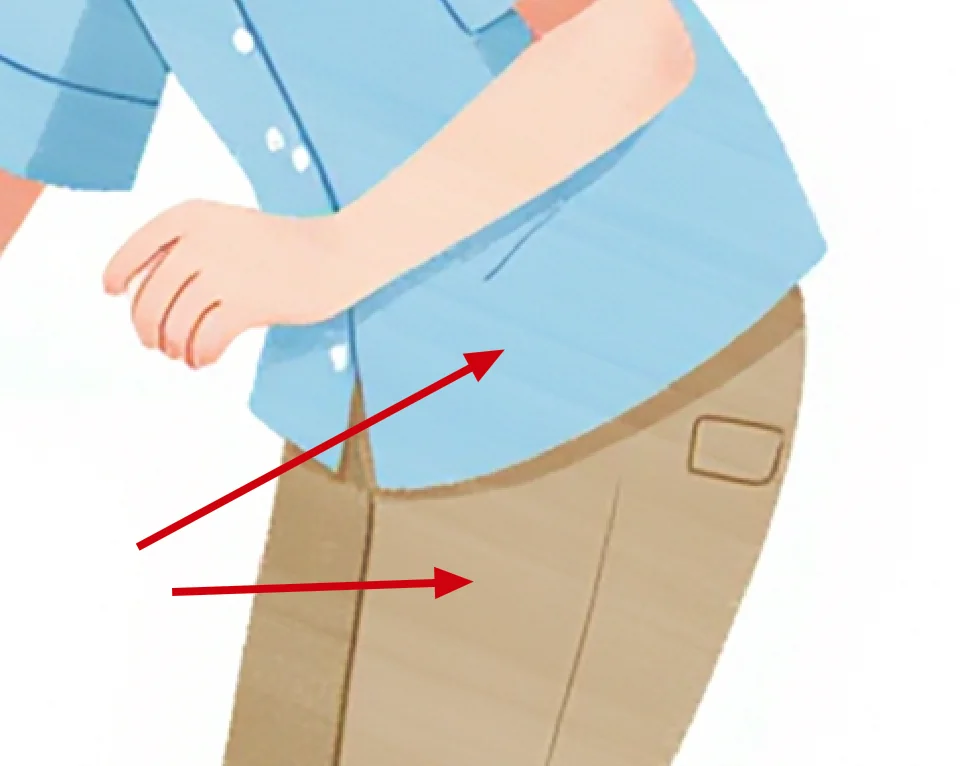 微妙的涂抹痕迹。
微妙的涂抹痕迹。
这么细微的风格特征,训练Lora时捕捉不到,但通过PS二次加工也能实现。传统做法是找水彩或铅笔质感的PS笔刷,用半透明的白色在图上刷一遍。但我要的是自动化,得让这个过程标准化,略微牺牲一点效果也没关系。
其实这本质是往图片上叠一层纹理。纹理有随机性,有的地方更透,有的地方更实,像从飞机上透过云层看大地。纹理的随机模式不同,最终形成了不同的笔触质感。我只要想办法试出这两种纹理,就可以用在所有图上,实现自动化。

这难不倒身为设计师的我。找素材啊,往测试图上叠,一层又一层。把图层模式设成滤色和颜色加深,消除纹理的本色,让它只影响图片明暗。很快就调出了这两种纹理,保存成PSD文件。
接下来做PS批处理程序。不熟悉PS的人可以这么理解,我打开一个开关,PS就开始记录我的所有动作。把复杂的图片处理流程先手动做一遍,停止记录,就产生了一个批处理动作。然后PS能对一整个文件夹里的图使用这个动作,就实现了自动化加纹理。

动作过程如下:
- 打开一张图片。
- 置入之前准备好的纹理PSD文件。
- 把纹理转换为图层,混合模式从正常改成穿透,里面的滤色和颜色加深才能生效。
- 合并所有图层,把纹理固化到图片上。
- 转成CMYK颜色模式,这是印刷工艺需要。
- 另存为TIFF格式,印刷需要的格式。
- 关闭图片。
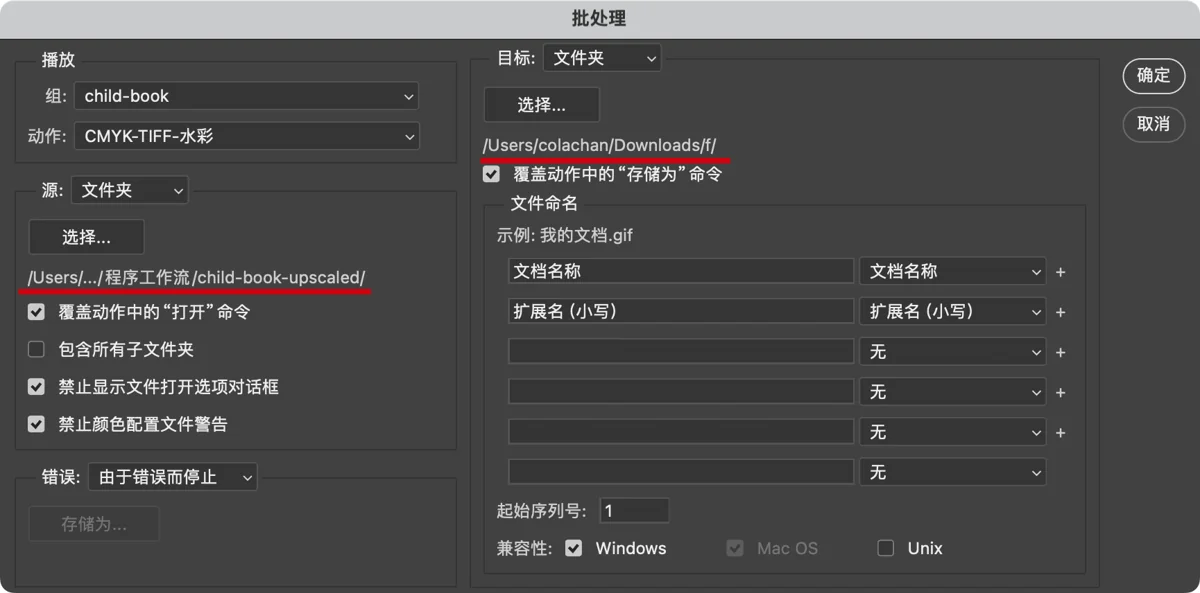
使用这个批处理动作时,打开图片和另存为会被新的设置覆盖,这样每次处理的都是不同的图片。
转换成CMYK的工作,在上一步Python里也可以实现,我一开始就是这么做的。但PIL包所用的颜色描述文件不专业,相比图像处理软件效果差很多,导致整张图发黄。和颜色相关的事情,还是适合PS来做。
PS批处理是非常强大的工具,关于它的高级用法,可以看我这篇文章:
△ △ △ 🔮 技术部分结束 🔮 △ △ △
开工
现在,万事就绪,开始接单。
按下启动开关,图哗啦啦出来
第1个实战项目图不多,1本书,82张图,给7天时间。
时间方面我自己这边是毫无压力,半天就全出来了。感觉像台照片打印机(如果不能比作印钞机的话)。

82张插图里,有一半左右没有人物。这种图片不容易出问题,往往首次生成就可用。所有图片进入重试流程的不到20张。我没有专门为手部问题重新生成,重试的几乎都是人物互动关系不太对的情况。
其中有3张图人物非常多,这类群像图指望AI一步到位是不现实的。我重新生成几次从中挑出问题较少的图,留给插画师修。
初稿提交客户,向客户说明插画师还未介入,先忽略手部问题,后续会集中修复。这样避免插画师做无用功,毕竟每一次改都是成本。
突遭变故,插画师退出
我这种一心钻到技术里的人,总是容易低估人的变数。
不过现在,还是先说说客户对初稿的反馈。说实话我是有点震惊的,修改意见那叫一个细。总结下来大概分几类:
- 细节不符合现实世界逻辑,比如课桌椅少了或者多了腿。
- AI漏了指定元素,比如画台灯漏了旋钮。
- 风格要求变了,比如模型训练图里,人物头发有表现高光阴影的线条,但客户要求去掉这些线条。
- 可能存在法律风险的内容,比如警察服装是外国样式。
- 印刷要求,比如夜晚和雷雨天的天空仍然要画成亮色,否则深色印刷出来效果会差。
- 美观要求,人物服装款式单一,要求多样化一些。
- 不太能理解的要求,比如小孩不能穿背带裤,长裤不能露脚踝,不能卷裤脚,笑不能露齿。嗯……难道是收到过这样的买家差评?
第一轮审稿意见,82张里有71张要修改,修改点远不止手部问题,那剩下6天时间给插画师就危险了。

和插画师一沟通,对方要求再次确认价格。这一确认,突然就变卦了,觉得价格太低,甚至连讲价都没讲,直接就退出了。
凭心而论,我给的价格确实不是很有诱惑力。加上这种给AI擦屁股的活,可能插画师内心多少是抵触的。
这时候,我朋友在给我另寻插画师,我自己也一直有在多方打听。结果不是很乐观,按目前市场水平,插画师们的心理价位其实比我的出价高很多,甚至一些大厂插画师能报出100一张的价格。而按照客户这边的审稿情况,后面几轮的修改量到底有多大,我心里也没底。即使让出大部分利润,高价找一个插画师合作,仍然有极大风险,成本兜不住。
咬牙自己改,试探AI的能耐
既然这样,这次我就自己来吧。一方面试探客户的修改意见到底能细到什么程度,以决定后续以什么标准来找插画师。另一方面也考验一下自己的AI能力,我虽是设计师,但不会画画,看我的AI技能+P图技能有没有本事兜底,让我有底气不完全依赖插画师。当然,我自认为PS技巧相当了得,这才敢继续干下去。

紧锣密鼓改了一周的图,经过6轮审稿,总共改了 71 + 60 + 33 + 11 + 3 + 13 = 191 张图。此刻我只想说一句“我滴个娘嘞”。其中个别图问题太多,我抛弃了原先的图全新生成,但这仅仅是减少问题,仍然需要局部调整。其余的图重新生成风险较高,容易引入新问题,最好是在现有图片基础上修补。所有这些修补只能手动。
这样一来,生图系统的自动化流程就遇到了巨大堵点。在生成图片和高清放大之间,大量手动修图代替了原先的简单挑图。
意外的是,这一周修下来,除了时间紧张忙得我手抖外,进展还算顺利。客户的要求本想着尽量满足,搞不定的只能协商一下,以没有插画师为由让对方考虑变通方案。结果全部要求都通过各种技巧的组合满足了,竟然没有搞不定的。至于改这么多轮,那是客户方面工作流程就这样。每一轮的修改意见都是之前没提过的点,审稿审不到那么全面,并非修改不到位。

所有要求都满足,但我完全不会画画,这是怎么做到的呢?光用AI改图是不现实的,AI画图难以精确控制。好在我有PS技巧,可以用各种手段让AI乖乖就范:
- 小范围擦除类任务,只用PS就能完成。
- 大范围擦除类任务,用豆包的局部重绘又快又好。
- 元素移动变形类任务,也是PS的传统强项。
- 无精确要求的创造类任务,用AI工作流局部重绘,可保画风一致。
- 对物体有精确要求的创造类任务,则通过从网上搜图,让AI局部重绘或转绘,保持了主体,又匹配了风格。
这些技巧,在下面的技术部分我会展开讲讲。
🔮 技术分享
▽ ▽ ▽ 🔮 技术部分开始 🔮 ▽ ▽ ▽
这部分已经脱离自动化的范畴了,都是手动改图遇到的难点和解决办法。
技巧与用途
首先,介绍一下用到的各种技巧,以及它们的能力:
- 【Flux】文生图局部重绘(高降噪值):完全替换掉图里某个元素。
- 【Flux】文生图局部重绘(低降噪值):把图中元素画得更细致,常用于修手。
- 【Flux】图生图局部重绘:把指定物体放到图片中。
- 【Flux】转绘:参照图中元素和风格,重画一张,用来把照片变成插图,或者融合不同风格的物体。
- 【豆包】对话改图:快速大范围改色、擦除物体,但画风保持不太稳定。
- 【豆包】局部重绘:精确局部擦除,好处是可以直接修改放大后的高清图,丢给Flux处理则奇慢无比。
- 【PS】快速选择工具:通过大致涂抹选中一个物体,颜色相近的部分也会自动选上,便于分离出来。
- 【PS】魔棒工具:完全根据颜色选择,可以设定颜色的筛选范围,适合选中树枝、树叶等形状非常复杂的物体。
- 【PS】污点修复画笔:低配版局部重绘,在简单背景的表现上不输豆包。
- 【PS】内容识别填充:效果比污点修复画笔更好一些,但需要先圈选再填充,而且会产生新图层,不太方便。
- 【PS】仿制图章:把一处画面画到另一处位置,经常用来修补两种颜色的边界线,沿着边界一路抹过去,可以把断开的线接上。
- 【PS】涂抹工具:就是字面意思,像小孩在餐桌上按着饭菜一顿乱涂,它与仿制图章相反,可以把一些不想要的边界线涂乱,让它们不那么明显。
- 【PS】操控变形:把一个物体局部钉住,拖动剩余部分,物体就像橡皮一样任你弯折。可以让人物抬头低头、弯起胳膊伸直腿。
- 【PS】色阶与色相饱和度调整图层:改变亮度和颜色,配合剪贴蒙版可以只应用在画面局部,轻松修改衣服颜色。
- 【PS】木刻滤镜:把画面的颜色降到只剩几种,这是滤镜库里能把图片处理成扁平风格的最佳工具。
接下来,看看这些技巧的组合如何解决一些疑难问题。
难题1:交警指挥交通
关键技巧:豆包局部重绘、内容识别填充、木刻滤镜

有趣的是,这张插图的难点竟然来自文化原因。Flux是一个德国团队训练出来的模型,它的训练数据里,中国的服饰元素显然不足。让它画一张交警指挥交通,它画出的交警服完全是外国样式。但童书上不能出现这种问题。
文生图局部重绘,降噪值1,明确要求它画蓝色短袖中国交警衬衫。然后就会出现如下情况:
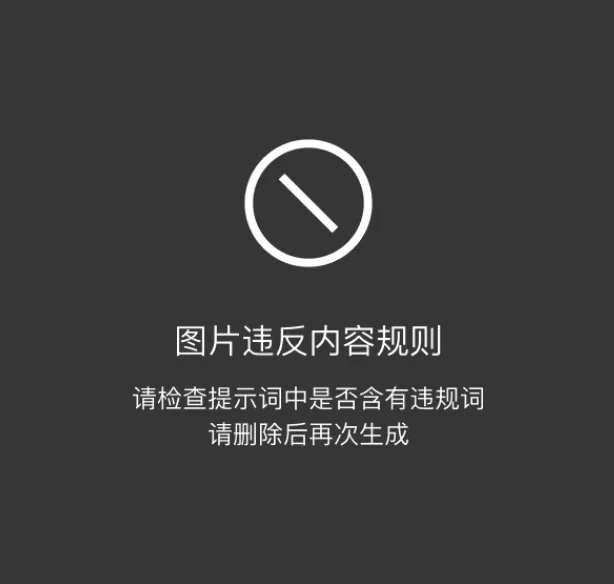
这是Liblib的限制,禁止生成一些可能有法律风险的内容。无论是提示词里带有“警察”,还是生成的图太像警服,都会触发屏蔽。当然,你也可以选择一些没有屏蔽的平台,不过Liblib它便宜啊,是没有好显卡时的绝佳选择。

但如果去掉警察相关的词,画出来真的就是很普通的短袖蓝衬衫,不像警服了。写也不是,不写也不是。

既然Liblib上的Flux这么扭捏,不如试试别的工具。豆包的即梦模型没有这个限制,而且效果不错,大概样子就出来了。

白色交警帽难度更高,豆包也画不对,像高档酒店门口的停车引导员。白色交警帽样式有它鲜明特征,特征少了,相似度会直线下降。

可以找个角度大致吻合的交警帽P上去。注意,为了避免被屏蔽,先用PS把上面的警徽给擦掉,等图片不必经手AI了再加回来。这里能看到PS内容识别填充的威力,轻松就把警徽去掉了。

把帽子摆好位置,现在还是写实风格。
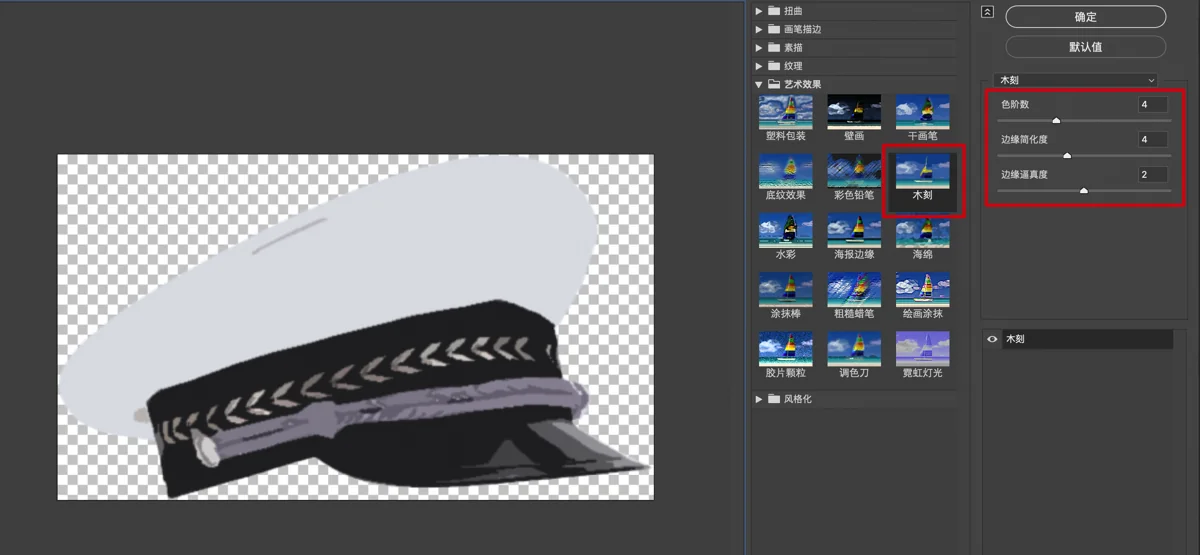
给帽子加上木刻滤镜,减少颜色数量,风格一下就变扁平了。

没有那么违和了,难题解决。当然,图里还有很多其他问题,都有比较稳定可靠的修复方法,这里就不讲了。
难题2:跳绳的小孩
关键技巧:文生图局部重绘(低降噪值)、转绘、操控变形

这张插图又触及Flux的能力边界了。它跳绳的场面肯定见太少,画的都是小孩胡乱挥舞绳子,甚至能有绳子就已经不错了。本想大力出奇迹,一口气生成16张图,居然一张能用的都没有。

不过没关系,只要动作对,跳绳可以画上去。这张最有改造潜力,PS胡乱画个跳绳,就有点像那么回事了。
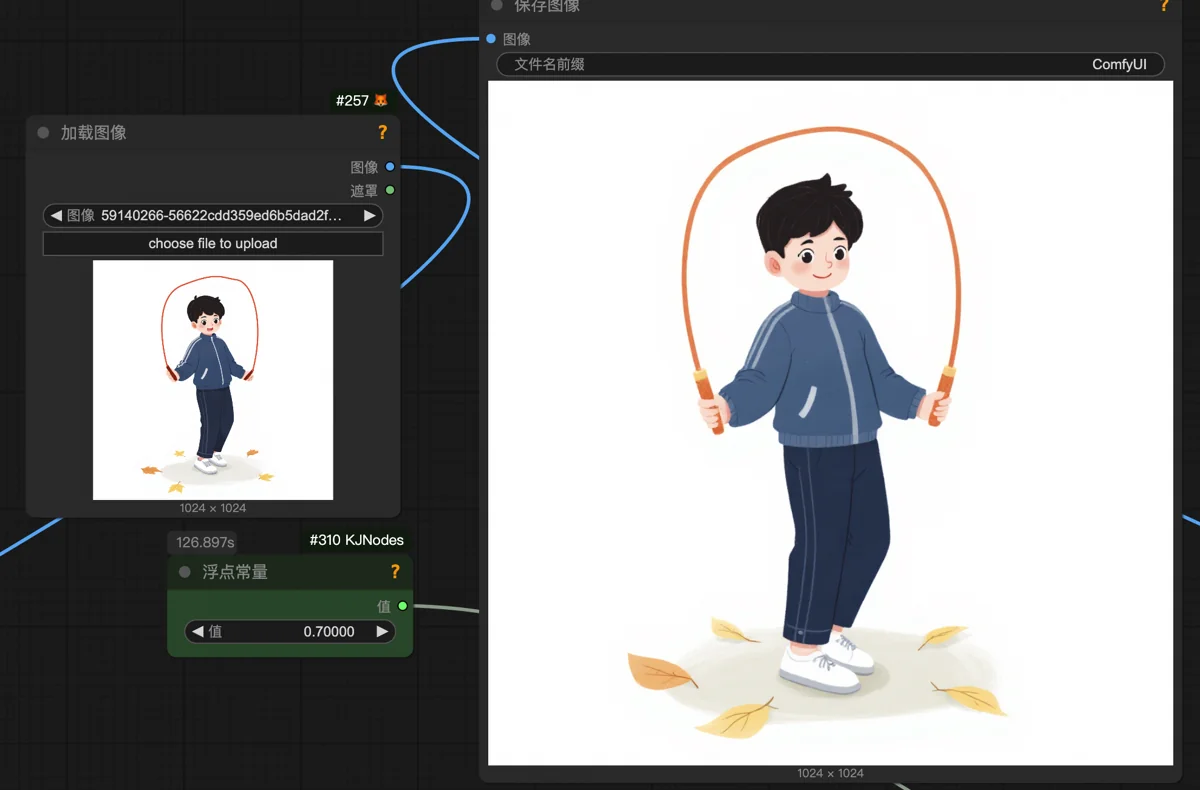
使用转绘工作流,降噪值设为0.7。大体保持原图内容,留给AI的发挥余地足够让它把跳绳画得更真实。

这里展开讲讲手部的修复。可以看到小孩右手没有拇指,或者说拇指和食指连成一片了。虽然可以直接在这张图上局部重绘,但手持物体的情况,AI往往画不好,大量重试都不一定能成功。

对于这种面积很小的手部,AI修不好是正常的,因为分配的注意力太少了。修手的关键不是局部重绘,而是放大。放大之后清晰很多,细节足够,虽然手仍然是坏的,但修起来成功率就高多了。
不过,如果Flux直接在完整的高清图上局部重绘,不仅速度非常慢,而且偏离Flux擅长的生成尺寸,很容易崩。解决办法是把要修的部分单独裁剪出来,取一块1024×1024大小的图片,这是Flux最擅长的尺寸,可以保障生成效果。修完了再贴回去。
可是贴回去的时候准确对位置很费劲啊,这就要借助程序来精确处理了。

回顾一下之前飞书多维表里的x和y坐标列,它是我放大裁剪和粘贴程序的一部分。我的裁剪程序可以把图片划分成5×5=25个切片,每个1024×1024,切片之间可以相互重叠。我在多维表里填上切片的行列号,比如上图取第2列(x为2)第3行(y为3)的切片,这个目测就能看出来。然后运行裁剪程序,它就能把这块切片单独存出来。

再对切片图用局部重绘,一次成功。降噪值可以看情况调整,原先的手问题很大,降噪值就要高。反过来,如果像本图情况,手的大部分姿势是对的,降噪值就要低,避免引入新问题。

再运行配套的粘贴程序,它根据裁剪时的行列序号,准确把切片贴回原图上。
不过这个人物的姿态还是不太自然,客户提过这样的意见,他们觉得人物站在地面不像是跳起来了。

也行,这个用PS就能处理:操控变形。先用快速选择工具把整个小腿和脚都选中,复制到新图层里。

开启操控变形,关节处用很多钉子钉住了。

按住鞋子往后一拉,腿就弯过来了。

再把原先的腿擦掉,就拗过来了。不过膝盖连接处有个小尖角没处理好,地面上也缺少投影,纯技术演示,小问题这里就不修了。
难题3:暴风雨中的柳树
关键技巧:转绘、豆包对话改图

画出来这枝繁叶茂的样子,笔直垂下的枝条甚至有点像榕树的气生根。

我想看看是Flux不认识柳树,还是被我的风格Lora污染了,在这种风格下所有树都画成这样。于是关掉Lora,去掉风格提示词,让它生成写实照片,发现它原来真的不认识柳树。

那就在这张基础上改吧。

先用豆包对话改图把树去掉,留下背景。

再想办法弄出一棵插画风格、枝条特征显著的柳树。直接网上找素材是最快捷的方法。

豆包对话改图把柳树改成彩色的。

用PS粗糙地拼起来。

经过几轮低降噪值转绘(0.3),效果就比较自然了。

最后把柳树叶子改亮一些,避免和乌云混在一起。雨滴的方向还不对,应该顺着风向。在分离背景那一步其实应该顺便去掉,最后在找素材加上。这里就不管了。
难题4:教室大扫除
关键技巧:文生图局部重绘(高降噪值)、图生图局部重绘、转绘

这个画面要体现一个小孩擦窗户,其他小孩在打扫别的地方。AI一遇到这种人物众多要求复杂的情况就漏洞百出。人物动作不合逻辑,课桌椅也缺胳膊少腿,没有一张能用的。

这些问题一个个修,不如找一张真实照片或手工插画来转绘。至少里面人物和环境都是合理的,在转绘过程中可能引入少量问题,但也比凭空生成的容易修。

降噪值开到1,转绘完,风格就拗过来了。

盆的造型太古老了,换个现代的盆。不过盆太深了,手也缺了,可以之后再修。其他小问题用简单的修补方法都可以搞定。
这张图的问题比我给客户的图少,有个典型问题没有出现:抹布造型。

在给客户的图片中,有一版过程稿里的抹布长这样。提示词里用的单词是rag,确实是抹布。但这个英文单词也有破布的意思,Flux就把它画成这样乱糟糟一团,像个拖把头。

文生图局部重绘,描述成a piece of cloth,一块布,反而变得更像正常的抹布了。所以有时候并不是画不出来,是没有找到合适的提示词。
手动改图遇到的疑难问题不止这些,但把前面列出的技巧组合使用,最终都有办法解决。
△ △ △ 🔮 技术部分结束 🔮 △ △ △
歇业
这单做完,评估了一下总修改量和所用时间,决定关门大吉不再接单。原因很简单,修改量太大,且时间紧张,单个插画师兼职不足以应付,得全职。如果单人全职,即使我一分不挣利润都给插画师,收入可能都不如上班打工,谁愿干啊?如果多人兼职,则要花过多精力在沟通上,还要疲于应付人员流动。
综合考虑下来,这生意实际上杠杆太小,见好就收吧。
至于这么复杂一套生图流程,构思、搭建和调试,总共投入了两个星期时间。但也没有白做,稍作修改便可以用来干别的,等有需要时再重新启用。
后记
这是一次在实际项目中密集使用AI的经历,让我得以感受AI对生产力的提升,也体会了AI到稳定商用的距离。
项目完成,有了喘息的时间,一边写下本文,一边回顾整个过程。想想还是震撼,毕竟从头到尾所有事情都是我一个人完成的。我没想到,儿童插画在AI的加持下是可以(部分)流水线生产的。我也没想到,AI能让一个不会画画的人顶大半个插画师。
当然,用AI终归是为了解决问题,不是为AI而AI。现阶段AI不是万能药,它不行的部分,要用传统手段来提供可靠保障。AI是柔性的、随机的,传统手段是刚性的、确定的,这两者结合起来用,就像建造一尊大型泥塑。全都用泥,整体软趴趴很难成型,但如果往一个木芯上面糊泥巴,则既稳固,又有细节。
就我个人而言,我敬重能把泥塑做得惟妙惟肖的手艺人,但我更愿意开一家生产木芯的流水线工厂赚钱。