带数字的成语,你一口气不停说,停顿5秒以上就算输,最多能说多少个?
先分享个小技巧:这游戏想要玩得好,优先想带“一”的成语。如果偶然想到带其他数字的成语,发散完没有头绪不要恋战,回到“一”来。而且,优先想“数字字字”和“字字数字”这种格式的词。
这技巧我怎么知道的?因为我对3万多个成语做了详细的数据分析,感兴趣请往下看。
数据准备
首先,要分析成语,先得把成语都找出来。稍微了解了下,不同词典收录的成语数量不同,数量范围在3-5万个之间。
在Modelscope找到一份数据集,包含3万多个成语,足以支撑我的研究:
https://modelscope.cn/datasets/Lawrenceshi/Idiom-solitaire
这个数据集本身也挺有意思,可能是为研究成语接龙而创建的。它把每个成语首字和尾字拼音都单列出来了。

不过我的研究方向有所不同,我只需要成语本身(word)和释义(explanation)两项足矣。

把成语中的数字词提取出来,单独一列,便于后续分析。
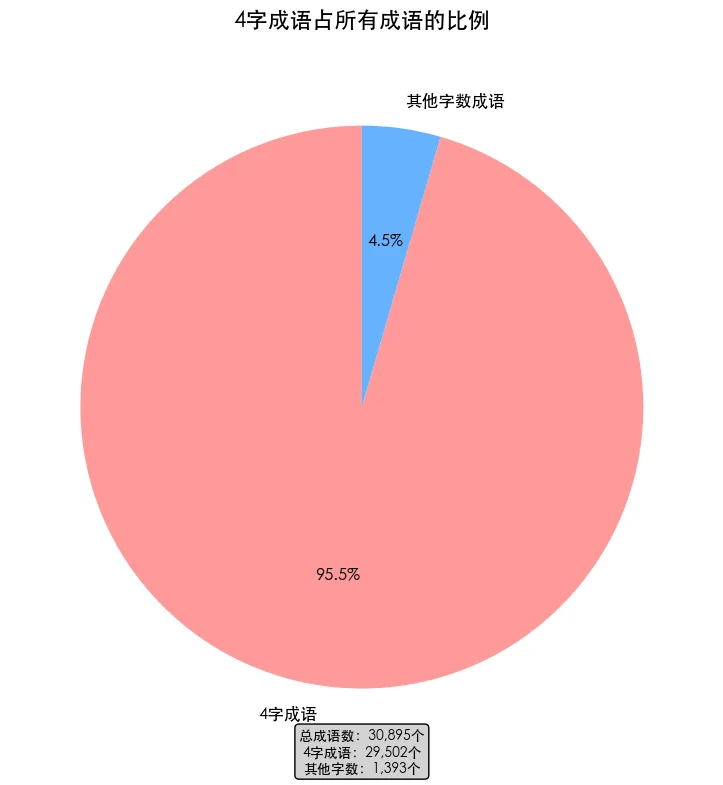
另外,成语中绝大多数都是四字成语,占比达到95%以上。我们提到“成语”这一概念时,更多还是指狭义的四字成语。虽然非四字成语也包含数字词,如“三下五除二”、“一而再,再而三”,但由于总量较小,排除掉对结果影响不会很大。
后续的研究都仅围绕四字成语展开。
成语中有哪些数字?
不过,提取数字词的过程中,我发现这事情不能深想,这里面水很深。
我们得定义一下这个课题本身。我研究的是成语中的“数字词”,还是成语中的“数字”?
这完全是2个概念。前者只需看常规的数字词是否出现,后者要关注成语中是否出现表达数字的含义。由于研究对象本身就是一种文化现象,我认为应该从含义的角度出发。所以,成语中的数字,要把那些“是数字词但表达含义不是数字”的剔除掉,同时还要把“不是数字词但含义等同于数字”的包括进来。
任务难度提高,我们一步步来。先看“是数字词但表达含义不是数字”这种情况,真的存在吗?
狭义的数字词有“一二三四五六七八九十百千万亿”这些。经过研究发现,它们在成语中无论是实指还是虚指,都没有脱离数的含义。顶多是类似于“三”泛化为“多”这样的用法,但它们的含义是从一个具体的数发展出来的,仍然可以视作数字。
“不是数字词但含义等同于数字”的情况呢?
应该马上有人能想到,“二”和“两”经常可以相互替代。没错,“二”确实是个很特殊的数字,它似乎有许多变体:“两”、“双”、“偶”、“再”、“复”。

我把其中部分变体也作为数字词,加到筛选条件中。把含有这些变体的成语单独提取出来,合并到一个专门的文件中,结合成语释义,交给AI判断它在里面表达的是不是数字的含义。结果如下:
- “两”字除了表达计量单位的意思,其余都是数字词。
- “双”全是数字词。
- “偶”只有“无独有偶”是数字词,其他的含义大多和“机会”有关。
- 为什么“再”、“复”不算数字2的变体?因为它们加了一层时间含义,第二次,有明确的“先”与“后”的概念,与纯粹的数值不同。
- 其他数字有没有这样的变体?完全等同的精确指代没有。“众”、“群”等模糊指代有的,但这些不是确切的数,我认为不能算进来。
- 我不放心AI,又人工筛选了一遍,发现Gemini 2.5 Pro其实准确率非常高。人工筛选的和它筛选的结果对比,AI只有3处遗漏,而且还发现了我的一处判断错误。
我尝试思考,为什么只有“二”有这么多变体,其他数字却没有?
一番查证,发现“二”在中华文化里真的很特殊。我们是一个高度崇尚二元论的文明,古代哲学中处处可见阴阳、乾坤、虚实等对立统一的世界观,导致数字2在文化上有大量衍生和泛化。比如“两”这个字,是符合二元论哲学的典型,它最初的意思是“天然成对的事物”,从字形上也能看出来,与“二”纯粹指代序数有所不同。想一想,只能用“两”不能用“二”的场合,是不是有许多事物都是成对的、或者对称的?另外,大写数字“贰”的来历,里面加入的这个“贝”字,也是在借用贝壳两半成对的含义。
展开分析
言归正传。既然我们把“带有数字含义”的四字成语都成功筛选出来,研究可以正式开始了。
带数字成语的比例
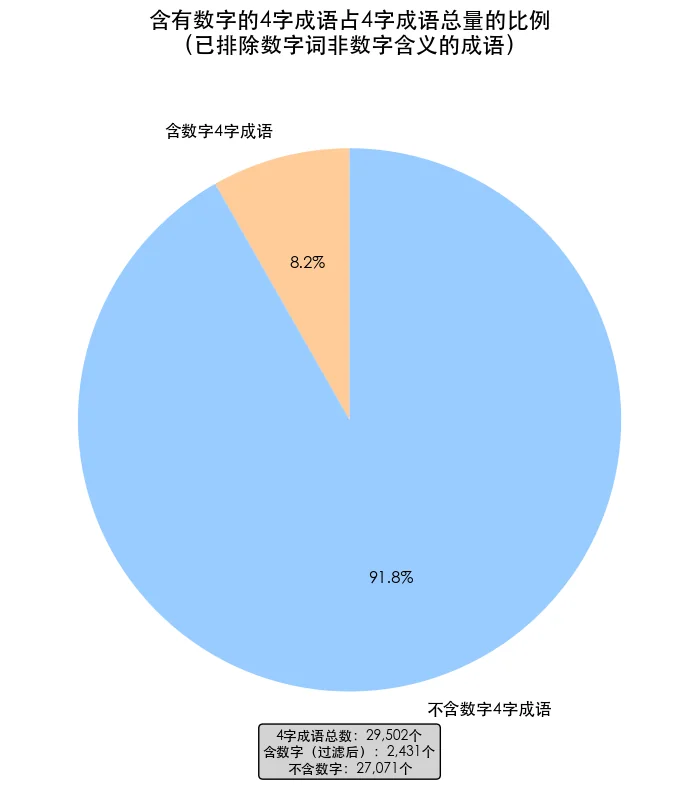
在29502个四字成语中,有2431个带有数字含义,占总量的8.2%。
成语数字词出现频率
在后续的分析中,我把含义相同的数字词都算到同一个数上,也就是把“两”、“双”、“偶”的数据都归到“二”里。为表示它是广义的数字“二”,我把它写作“(2)”。
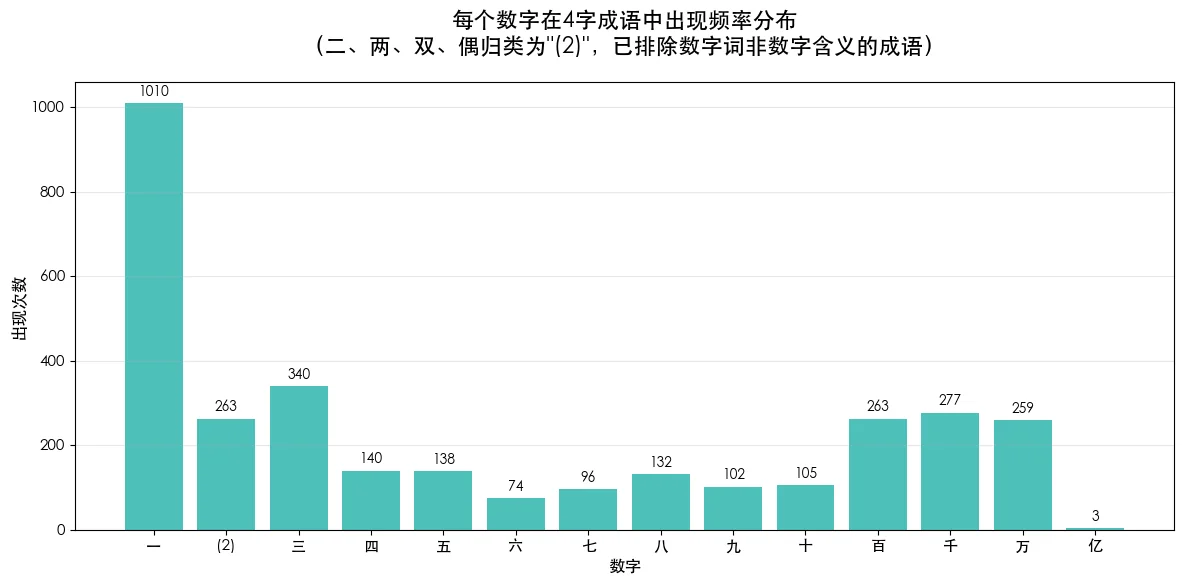
数字词出现频率的规律:
- “一”遥遥领先,约是第二名的3倍。
- 两头高中间低。“一二三”、“百千万”用得多,普遍为中间数字的2倍多。可见古人造词也爱走极端,不夸张不足以抓人眼球。
- “亿”几乎没人用。
关于“亿”可以多说几句。我做研究前就认为它在成语中应该极少出现,把它加进来分析是作为“对照组”。因为“亿”是这里面唯一一个万进制数字,其他都是十进制数字。
从十开始,每个数字10倍递进。到了万之后,这几乎触及古人日常生活中的数量级天花板,再往上没有造词的必要了。但统治者不同,统治者处理天文数字。只是他同样不能再往上造词了,因为上面数量级太多,造多了根本记不住。采用“民间”最高数量级万来递进,中间的用复合单位来表示,十万、百万、千万、万万=亿……这样一个体系,既不增加新概念,又能很好表达各数量级的大数。
我在这篇文章里详细解释了这个观点:为什么英语中没有万这个单位?
成语数字词的数量
四字成语中,数字词占了其中几个字?
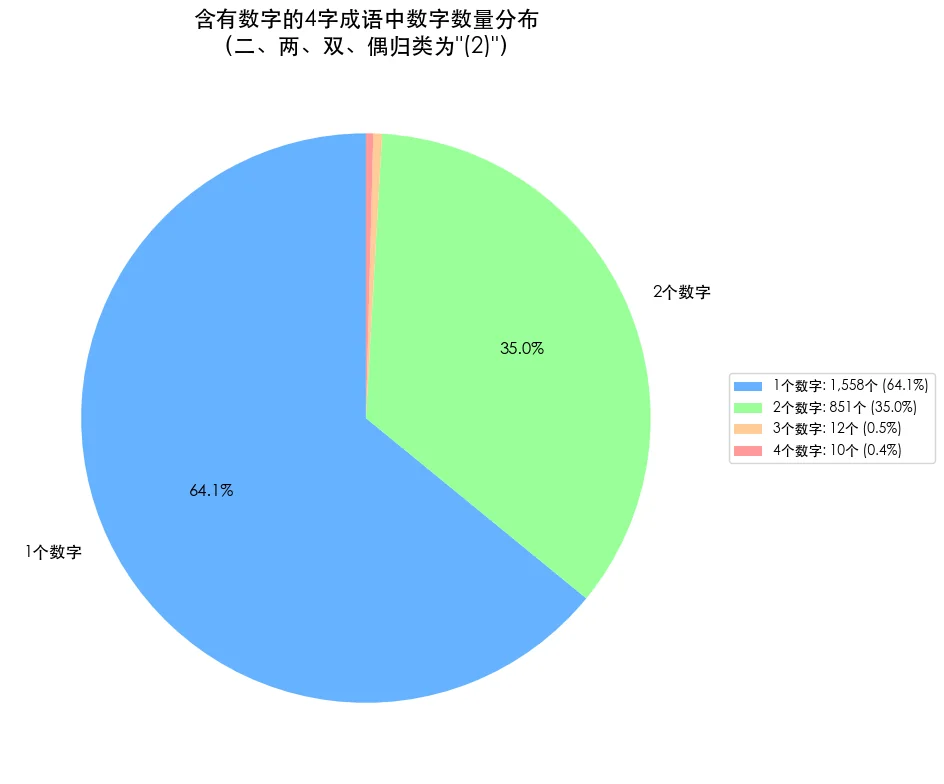
1个数字词的成语占64.1%,2个占35%,这两者加起来就99.1%了,3个和4个的极少。
3个的如“三六九等”,4个的如“一五一十”。
看到这里不得不说,成语真是文化的高度浓缩,可以说是意义的多层包浆。想象一个不懂中文的歪果仁看盯着“一五一十”这个词:
One, five, one, ten?是说一个东西是另一个两倍那么厉害吗?
成语数字词组合
有2个及以上数字词出现时,它们是如何相互组合的?哪些数经常一起使用?
我先讲讲怎么看这图,它是一个条件概率热力图。先选一行横着看,再看其中某一列。
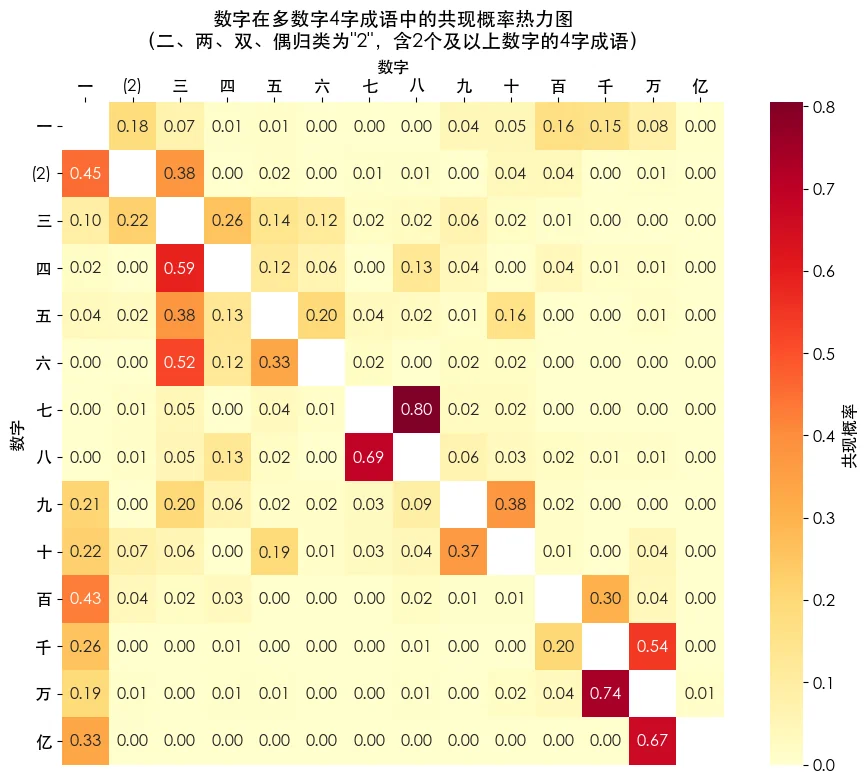
- 比如第“三”行第“四”列表示,所有含“三”的(2个数字词)成语中,也含有“四”的占了26%。
- 反过来,第“四”行第“三”列表示,所有含“四”的成语中,也含有“三”的占了59%。
严谨地解释一遍。这个图里每个格子的概率来自两个数相除,分母是包含行数字的成语数量,分子是同时包含行数字和列数字的成语数量,约束条件是所有带有2个及以上数字词的成语。
这张图上能看出的东西就非常丰富了:
- “一”雨露均沾,对其他数字没有明显偏好。
- “二三四五六”倾向于和相邻或相近的数组合,对“三”尤其依赖。如“两面三刀”、“三从四德”、“三令五申”、“五脏六腑”。
- “七八”是好基友,基本只认彼此。如“七上八下”。
- “九十”组合也非常常见,两个大数表示多。如“十拿九稳”。
- 较大的偶数有“减半组合”现象,和自身的1/2组合,比其它数字明显高一些。如“三头六臂”、“四平八稳”、“五光十色”。
- “九”和“三”也构成了特殊的组合,尤其是“九”依赖“三”,如“三教九流”。这里面莫非有平方的思想?
- 从“百”开始,大数的组合模式只剩两种:和“一”组合表示反差,如“一落千丈”;和相邻大数组合表示非常多,如“千头万绪”。
- 竖着看,“一”和“三”是最被需要的数字。这也与出现频率那章结论相符。
成语数字词重复
这里还有个小插曲。由于这分析代码是AI(Claude 4 Sonnet)写的,对于这种复杂的热力图,我不太信任AI的算法,特意验证了一遍。
怎么验证?热力图里的成语,每一个都包含至少2个数字词,每一行已经锁定了其中一个数字词,行里的格子是另一个数字词出现的概率。理论上,每一行的概率之和应该接近于1。但为什么不刚好是1,有两个因素会使概率之和偏移:
- 当成语中出现3个甚至更多不同数字词(如“三六九等”),会在多个格子中重复出现,分别独立计算概率,导致概率之和偏高。
- 当成语中仅有一种数字词但出现多次(如“一心一意”),它不会出现在任何一个格子里(其实它就在没有数字的对角线白格里),却会被算进分母中,导致概率之和偏低。
和AI讲了我这个观察,它认同偏高的原因,却不同意偏低的原因。它坚称每行概率之和理论上只会大于等于1,如果有小于一的情况是数据精度导致的误差。
我亲自一算就发现不对劲,第“一”行之和只有0.74,离1也太远了,精度再差也不能差掉1/4啊。
和AI来回拉锯几轮,它顶不住我的追问,决定在代码里写一些验算逻辑。验算完发现我是对的,偏低真是这个原因。
验算也让我发现了两个特殊数字。绝大部分数字概率之和都在1附近,上下偏离极小。但“一”的概率之和是0.74,“百”的概率之和是0.9,表明这两个数字词确实有大量重复出现的情况。
想想确实如此:“一朝一夕”、“一草一木”、“一唱一和”、“百战百胜”、“百发百中”、“百依百顺”……
成语数字词位置
再看看数字词在四字成语里通常出现在什么位置。
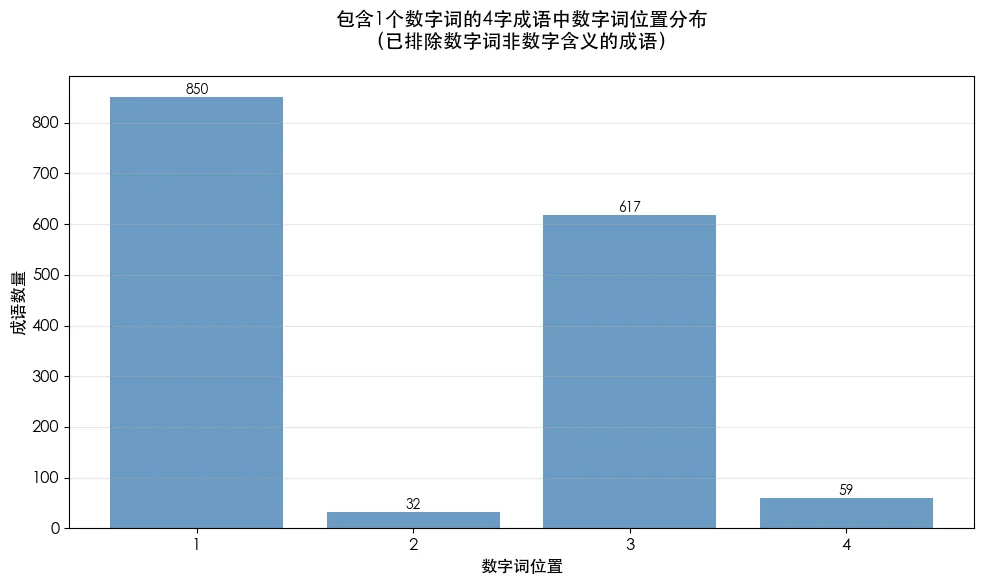
只包含一个数字词的成语,绝大部分数字都出现在第1个或第3个字。
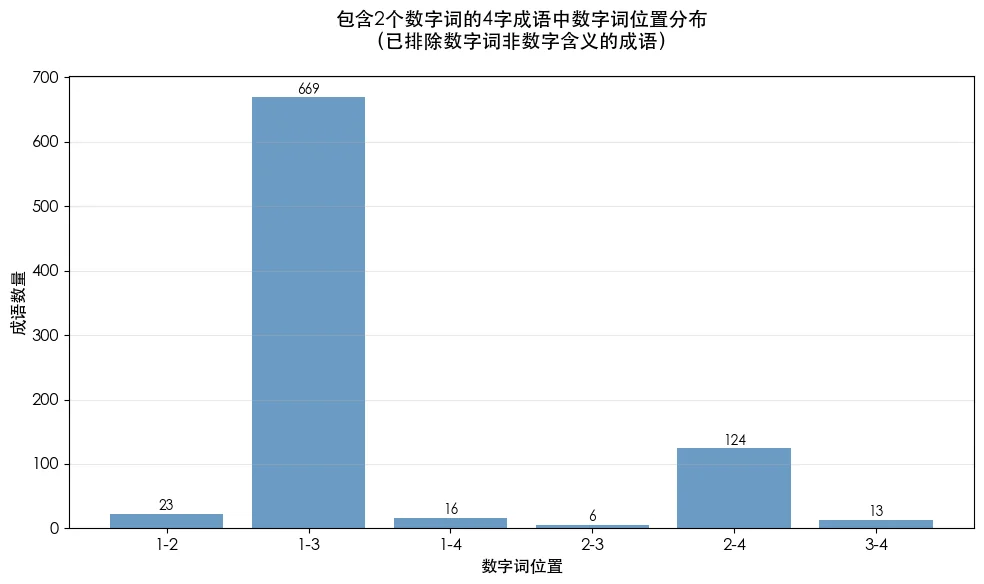
包含2个数字词的成语,数字位置就有6种组合:1-2型(数数字字)、1-3型(数字数字)、1-4型(数字字数)、2-3型(字数数字)、2-4型(字数字数)、3-4型(字字数数)。
1-3型占绝对主导,正是典型的“三番五次”模式。2-4型少很多,但也远超其他,“横七竖八”模式。
3个及以上数字词的成语就没什么好分析的了,总量才22个。
另外,只有1个数字词的成语还能继续挖掘,看看每个位置上都是些什么数字。
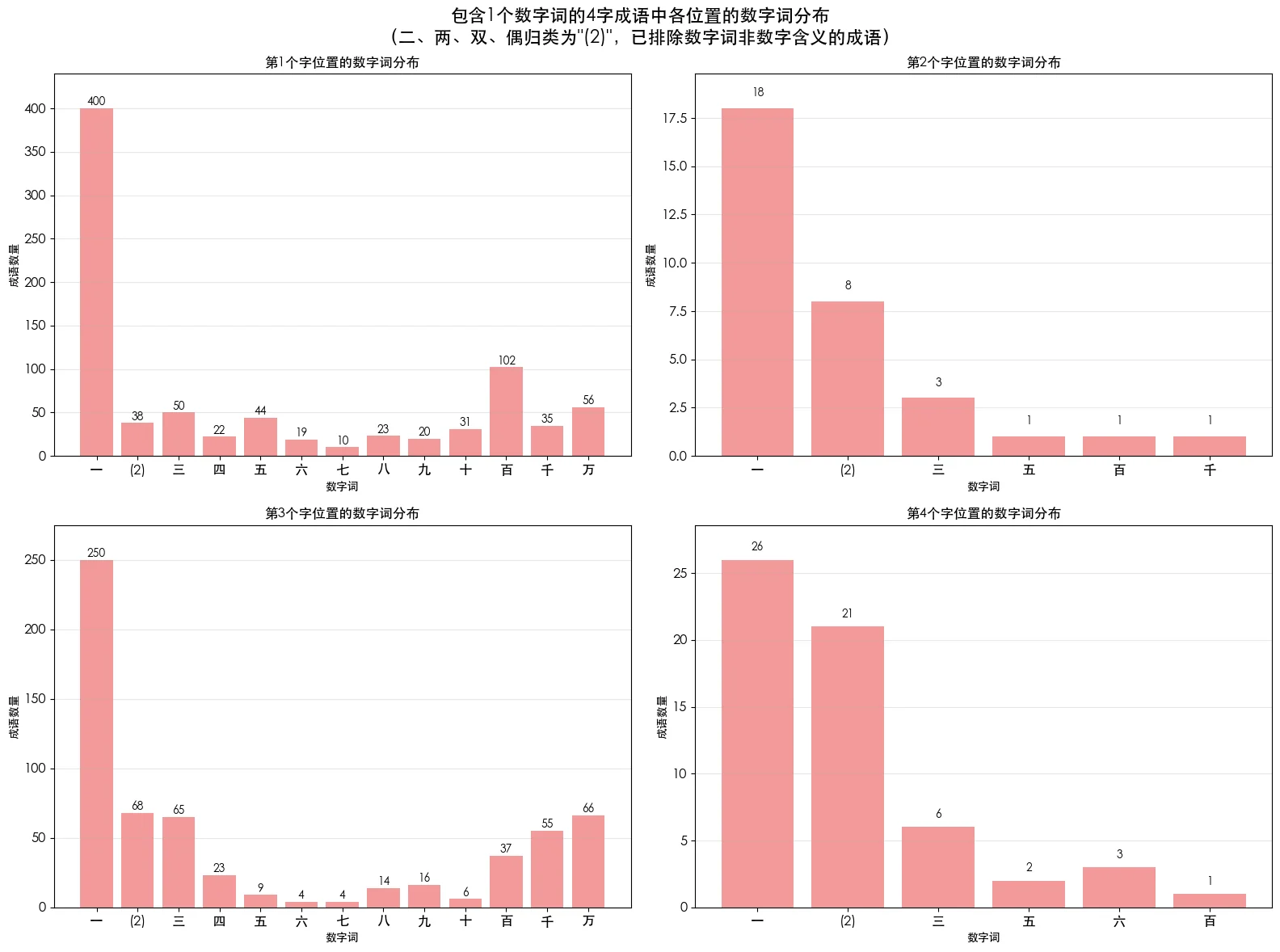
- 无论几号位,都是“一”最多,1号位和3号位领先优势尤其明显,一骑绝尘。
- 忽略“一”的领先,其他数字在1号位分布相对平均(除了“百”较多),而在3号位出现明显的微笑曲线式分布。
- “(2)”在2号位和4号位表现非常突出,相信“双”字在这里作出了巨大贡献。虽然比例可观,但总量其实很少,所以这两个位置的规律未必能说明什么。
关于微笑曲线我有个猜测。只有1个数字词的成语,和有2个数字词的成语,在语法结构上有明显不同。在这短短4个字里,1个数字的成语,前两字和后两字是有明确分工的,前者更倾向于表达事物本体,而后者更倾向于形容前者,比如“一飞冲天”。而2个数字的成语,前两字是一个一件事,后两字是另一件事,靠对仗排比的手法让人明白它的内涵,如“百媚千娇”。
- 回到1个数字的成语。既然前者是本体,考虑到文化和历史的丰富性,各种数字都可能出现,因为有许多约定俗成。如“五雷轰顶”,你不能随随便便换成“一雷”、“百雷”。
- 而后者是形容,所以可以怎么夸张怎么来,中间不大不小的数字用处不大。“雷霆万钧”和“雷霆九钧”哪个更有张力?你一看便知。
虽然也有倒过来的用法,如“不堪一击”。但你仔细品味,有没有觉得倒过来的用法似乎给人一种“倒装句”的感觉?汉语常规语序(包括古文)里是不是更多说“什么东西怎么样”?似乎主体先说出来对信息传递更有利,所以总体而言1号位数字更多是本体,3号位数字更多是形容,导致了这种差别。
成语数字词大小
再看看数字大小在四字成语中有什么规律。既然要比较大小,就至少得有2个数字词。由于3个和4个数字词的成语极少,这里只分析2个数字词的成语。
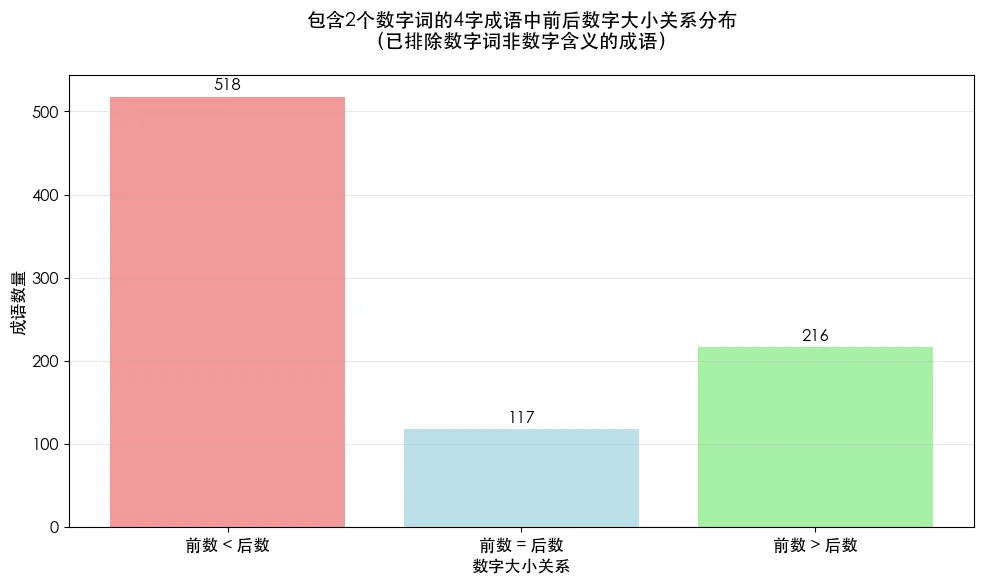
数字增大的情况占多数,减小的情况次之。两数相等其实就是重复使用,这种用法最少。可见数字增大的递进式表达更加自然,信息传递效果更佳。
再细看每种位置组合的大小情况,也就是:1-2型(数数字字)、1-3型(数字数字)、1-4型(数字字数)、2-3型(字数数字)、2-4型(字数字数)、3-4型(字字数数)。
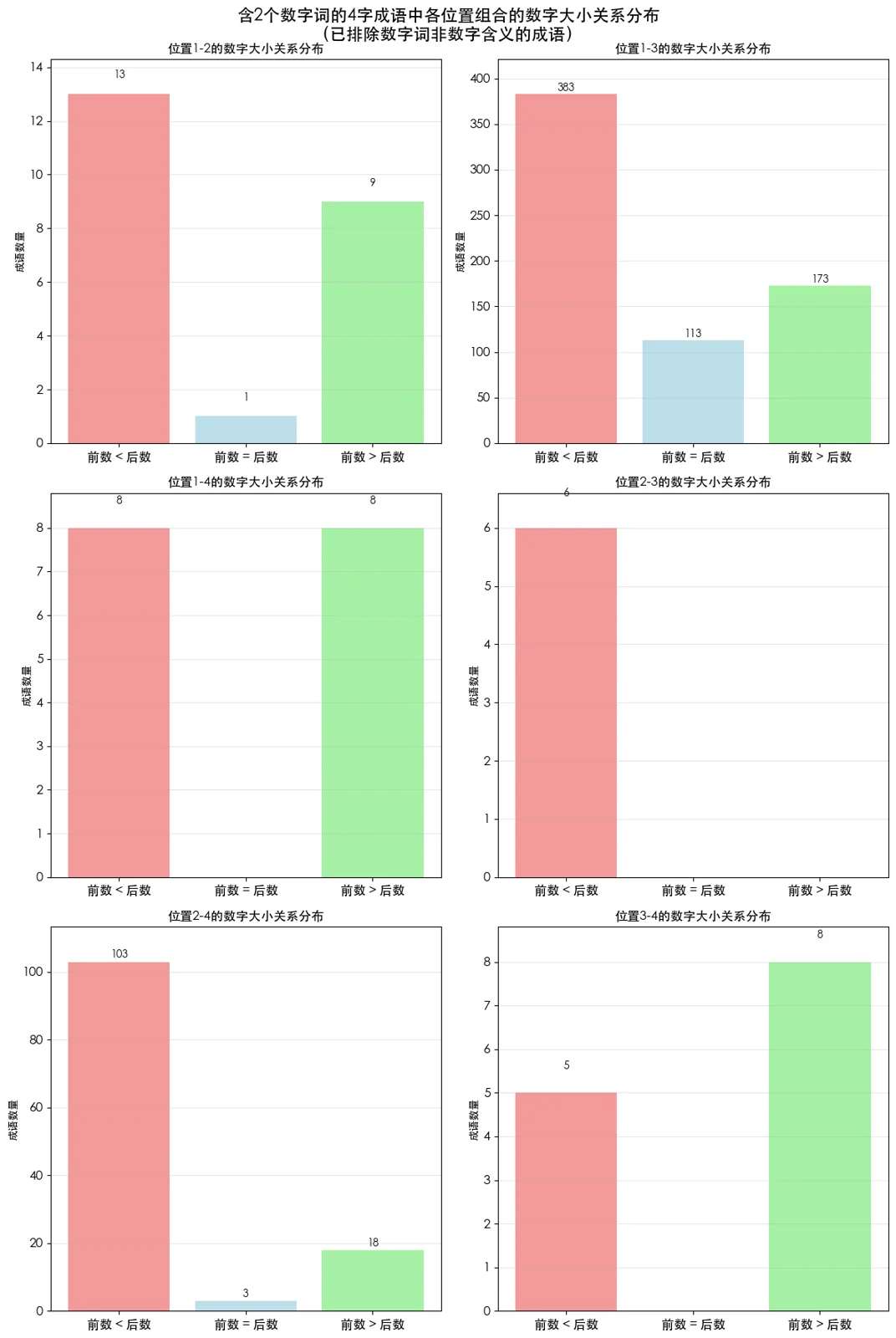
由于1-3型和2-4型占了绝大多数,我们重点看图2和图5:
- 1-3型的大小关系和整体情况接近。如“一石二鸟”、“双宿双飞”、“万紫千红”。
- 2-4型更极端,明显由数字增大的情况主导。如“隔三差五”,另两种模式我竟然一个也想不到。
- 其他类型数量太少,图表没什么意义。
成语数字词奇偶
奇数与偶数在汉语中也有显著区别。奇数为阳,偶数为阴。来看下(十以内)奇偶数在成语中的情况。
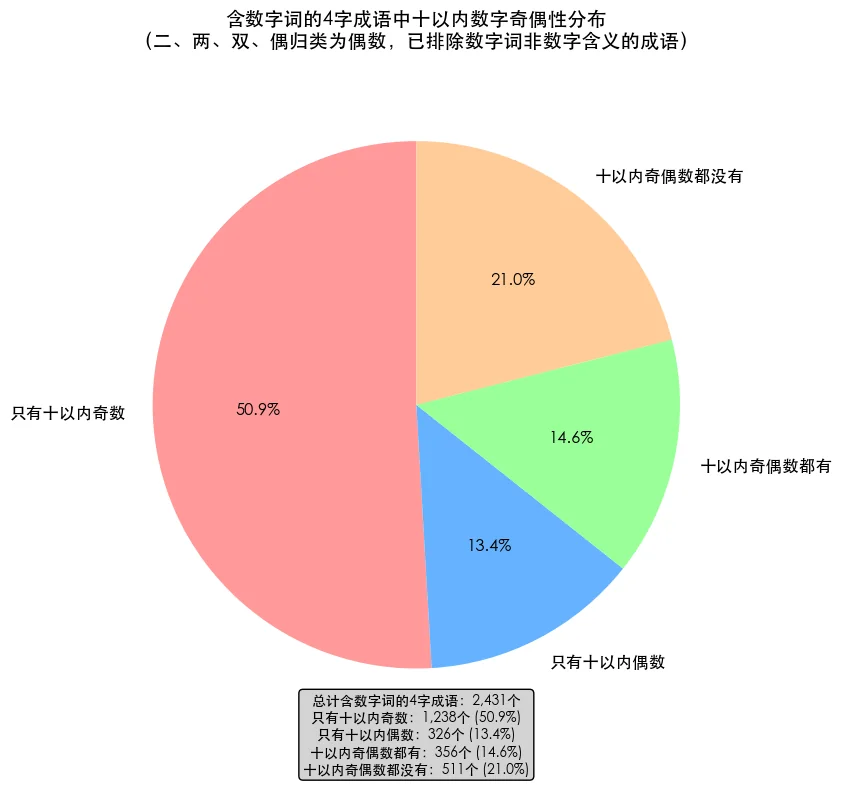
由于“一”傲视群雄的使用频率,仅含奇数的成语占到一半以上。仅含十以上大数的次之,奇偶数都有再次,最少的是仅含偶数的成语。看来阴数确实在文化上就矮一头,不受待见。
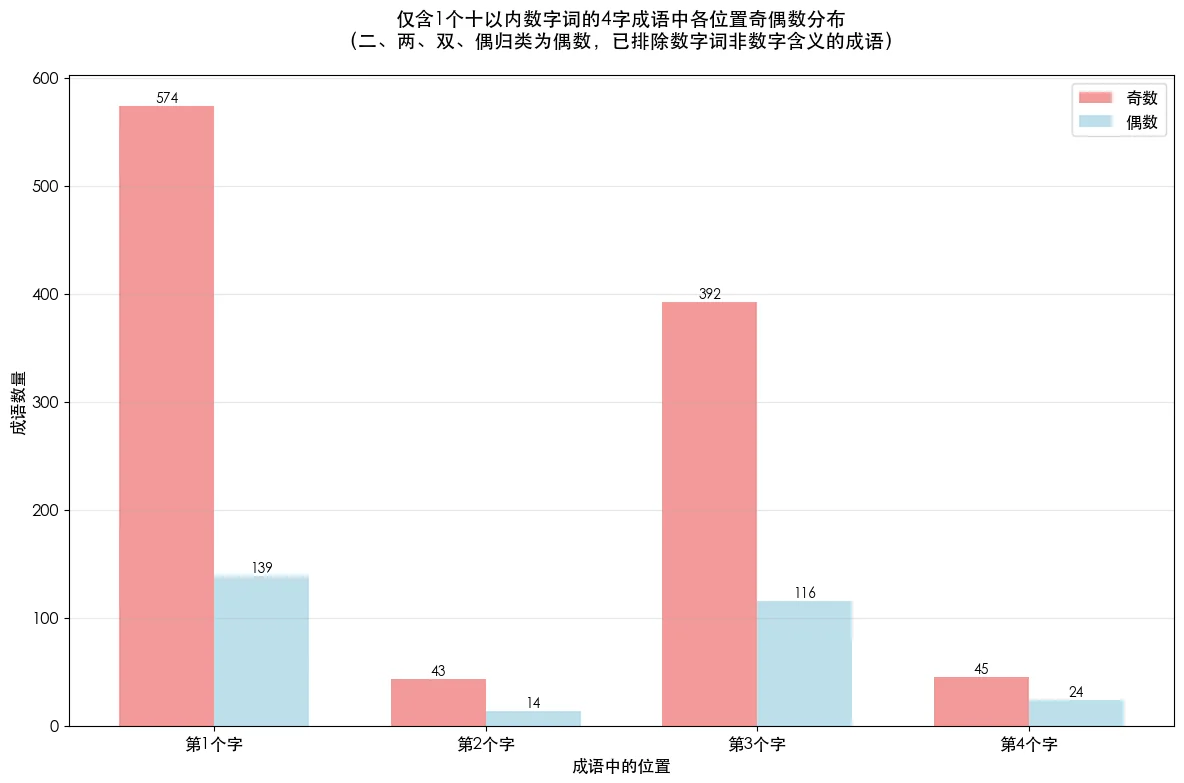
单独分析仅含1个数字词的成语,无论在几号位上,奇数都力压偶数,1号、3号位尤其明显。
到含2个数字词的成语里,情况就有变化了。这里我们只分析1-3型和2-4型成语,因为其他类型总数太少了。
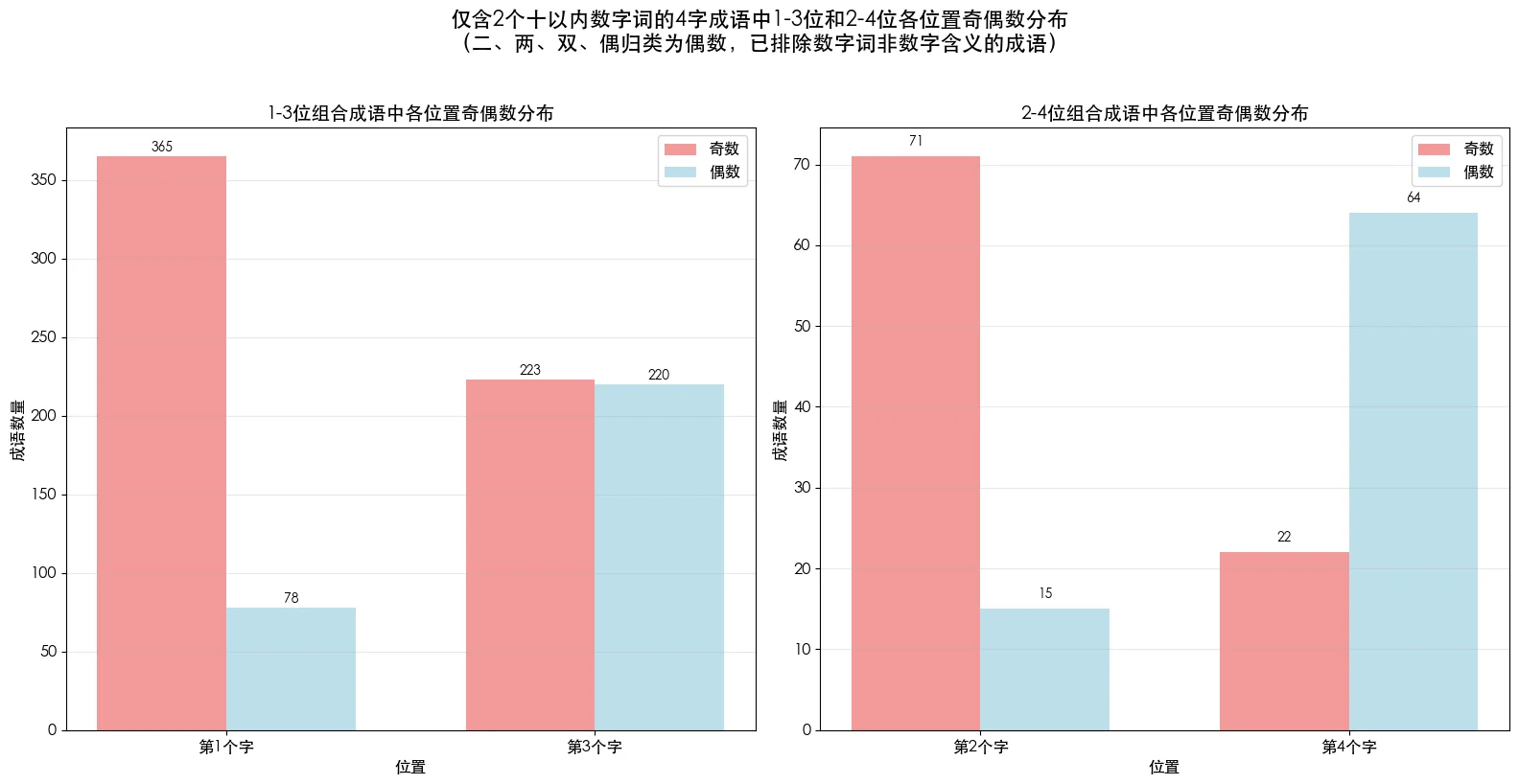
- 1-3型的1号位奇数占绝大多数,但3号位两者持平。当头先来一个阳数,后面可阳可阴,“一波三折”、“七上八下”。
- 2-4型的2号位也是奇数占绝大多数,但4号位完全反转。阳数还是得在前,阴数结尾,“丢三落四”、“横七竖八”。但这背后有什么文化原因,我还没想明白。
可见,无论从哪个角度,成语中的文化可以只用阳数,也欢迎阴阳调和,但基本拒绝只用阴数。
结语
数据分析这个技能很有意思。我学了它这一年多以来,没做过什么正经事,完全当玩具在用了。用来满足我的各种突发奇想,比如我之前还研究过英语单词重音的分布规律。
整一套分析下来,没有任何对生活有直接帮助的结论,纯粹图一乐呵。
不过,我更想知道语言学者和语文老师此刻感想,或许能联想到什么关键因素,从中挖掘出更多数据背后的文化和历史。如果你有新的发现,欢迎和我分享。
最后,开头的游戏你玩了吗?最高记录可以连续说多少个?