适合读者:学英语的朋友、搞数据分析的朋友、写Python的朋友、我的朋友
这是我的第一个数据分析项目。自学数据科学有一年多了,技能掌握了不少,实际项目一个没有。学数据分析时,analyze、analysis、analytical天天在面前晃悠,3个单词重音位置都不一样(‘analyze, a’nalysis, ana’lytical),太不友好了,读文章的时候舌头老打结。

重音位置的问题,有人说有规律,规则罗列一大堆;有人说例外太多,别找什么规律。细想,就拿这3个单词来说,规律真的有。英语似乎在极力避免3个连续非重音,且重音位置尽量靠前。在不超过5个音节的情况下,重音总在倒数第3个音节上。
感觉有它的道理,3个连续非重音太平淡了,听者提不起精神,重音可以增加变化。就像开车一路笔直不转弯特容易犯困。重音太靠后则会降低信息传递成功率,试想一个长单词前面的音都轻轻的,最后一个音节发重音,听者还没反应过来就结束了。
这点可能不太好想象,我用普通话来类比。普通话其实有个巨大的缺陷,就是这个“不”字。它的声母、韵母发音都非常轻,尤其和后面的字连读时,韵母还会变得更轻,你时常会分不清对方究竟有没有说这个“不”字。那可是完全相反的两种意思,严重阻碍沟通。我女儿哭闹时,我就分不清她到底是“要”还是“不要”。
回到英语重音的问题,我的猜测似乎像那么回事,但缺少证据支撑。现在,作为一个学习数据的人,是不是该自己动手拿数据验证一下,有多大比例的单词符合这个规律?
研究方案规划
学了数据分析后,研究思路很快就出来了。这个问题无非就是采集、清洗、分析、可视化,并不涉及回归分析和预测。
这是我目前掌握的技能,足以一试:
- 找一份全面的单词列表
- 找免费批量的方法,从在线词典获得音标信息
- 得出每个单词的音节数、重音位置,这一步可以借助AI
- 分析重音位置分布,数据可视化
- 验证我的猜想
下面逐一拆解。
数据来源
在知名数据科学社区Kaggle找到了一个数据集,就是个朴素的txt文件。其中包含了30多万个英文单词,按字母顺序排列,一行一个:
https://www.kaggle.com/datasets/bwandowando/479k-english-words

一个txt文件有4mb,看小说的人应该熟悉,这可是百万字级别的小说。
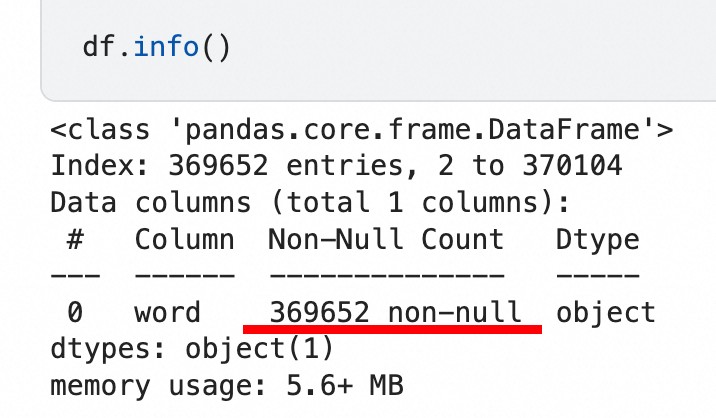
我在Kaggle创建了一个代码项目,数据集导进去,读出其中所有单词,得到了一张369652行、1列的表格。
查发音
表格里只有单词,要从词典里获取音标,研究才能严谨地继续下去。
运气不错,有个免费的在线词典API:https://dictionaryapi.dev/。
现在我需要把这30多万个单词,挨个拿到这个词典里去查。当然,不是手动的,要写代码跑。
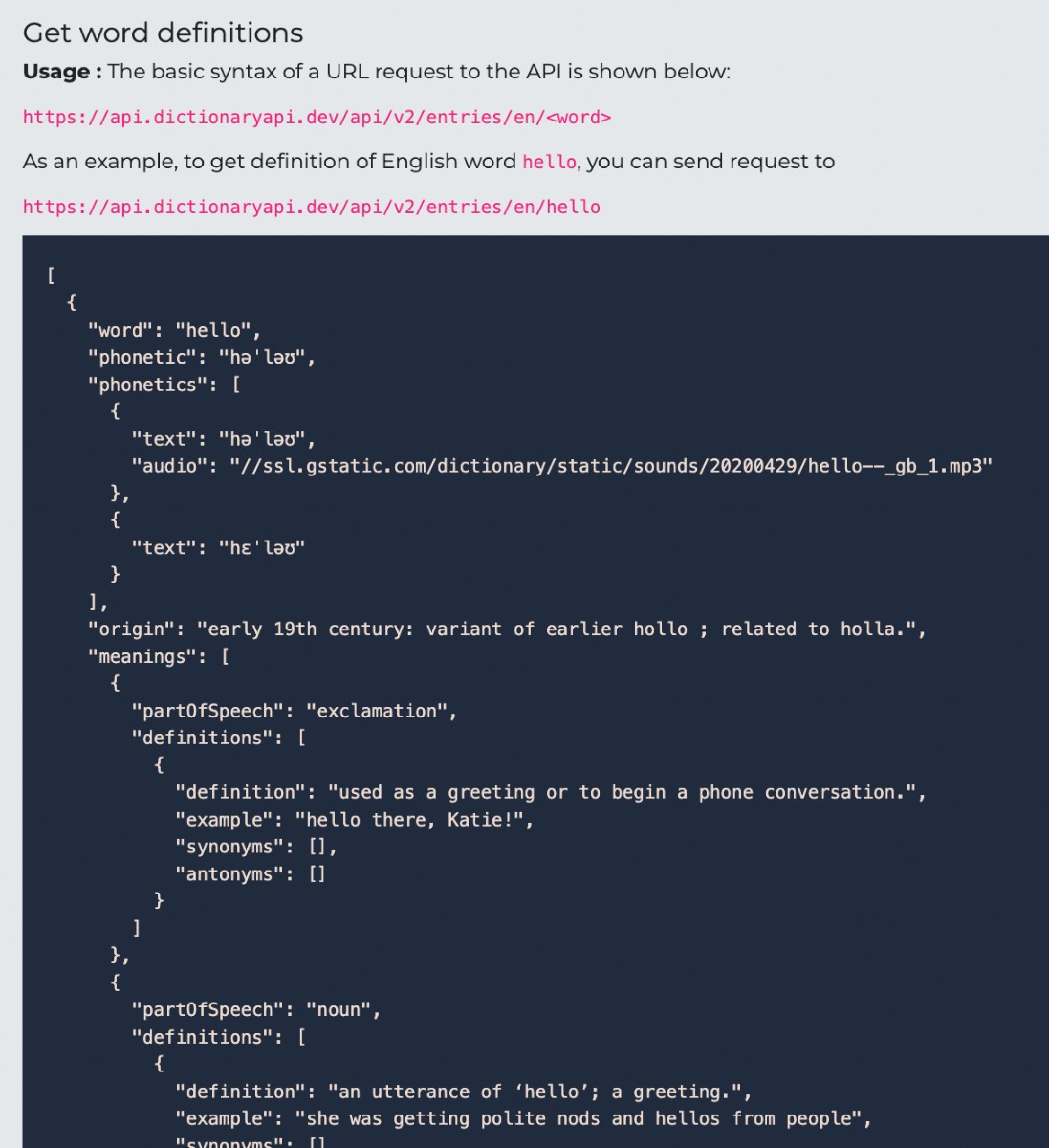
API返回的信息里,除了音标,还有发音的音频、词源、词性、意思和例句。这里可能有用的是音标、词源和词性。但绝大多数词源缺失,只拿了音标和词性。
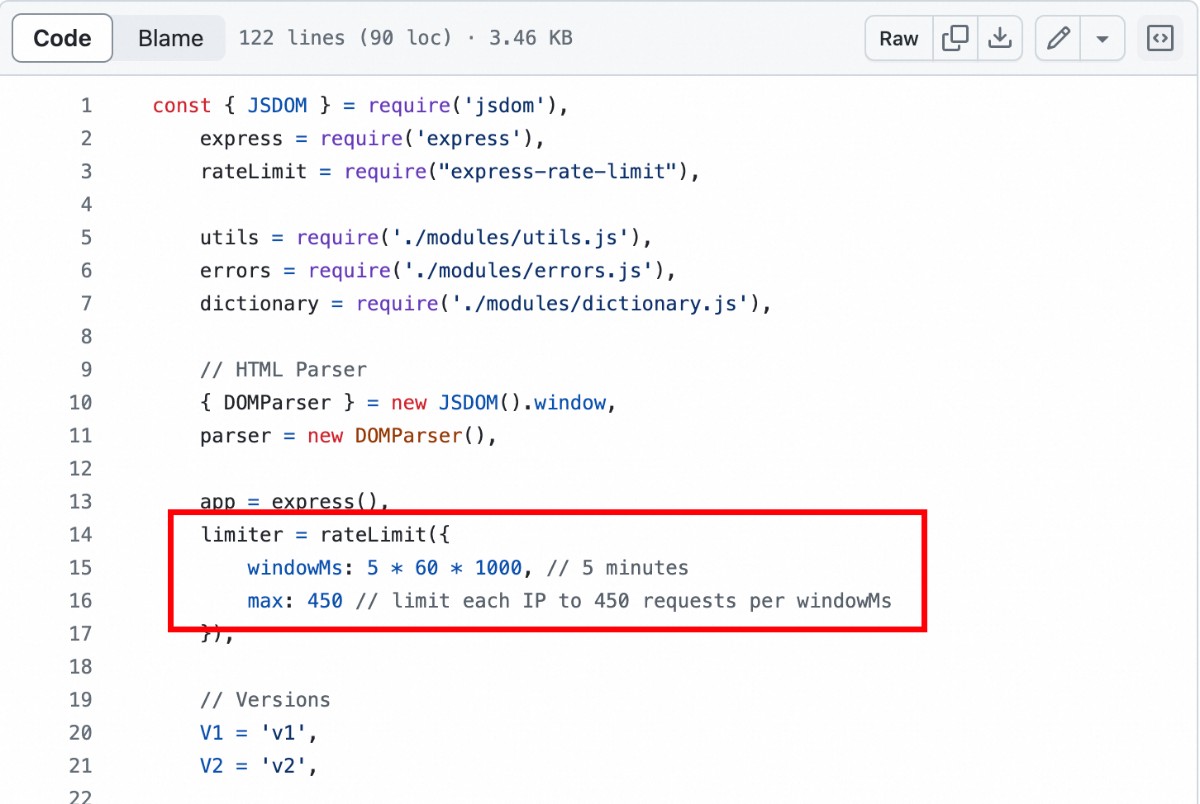
查音标过程中,遇到了数据量太大的问题。API文档没有提到请求的限制,终于在它的Github代码里找到了:每5分钟最多请求450次。这369652个单词,即使没日没夜地查,也要 369652/450*5/60 = 68.45 小时,将近3天!
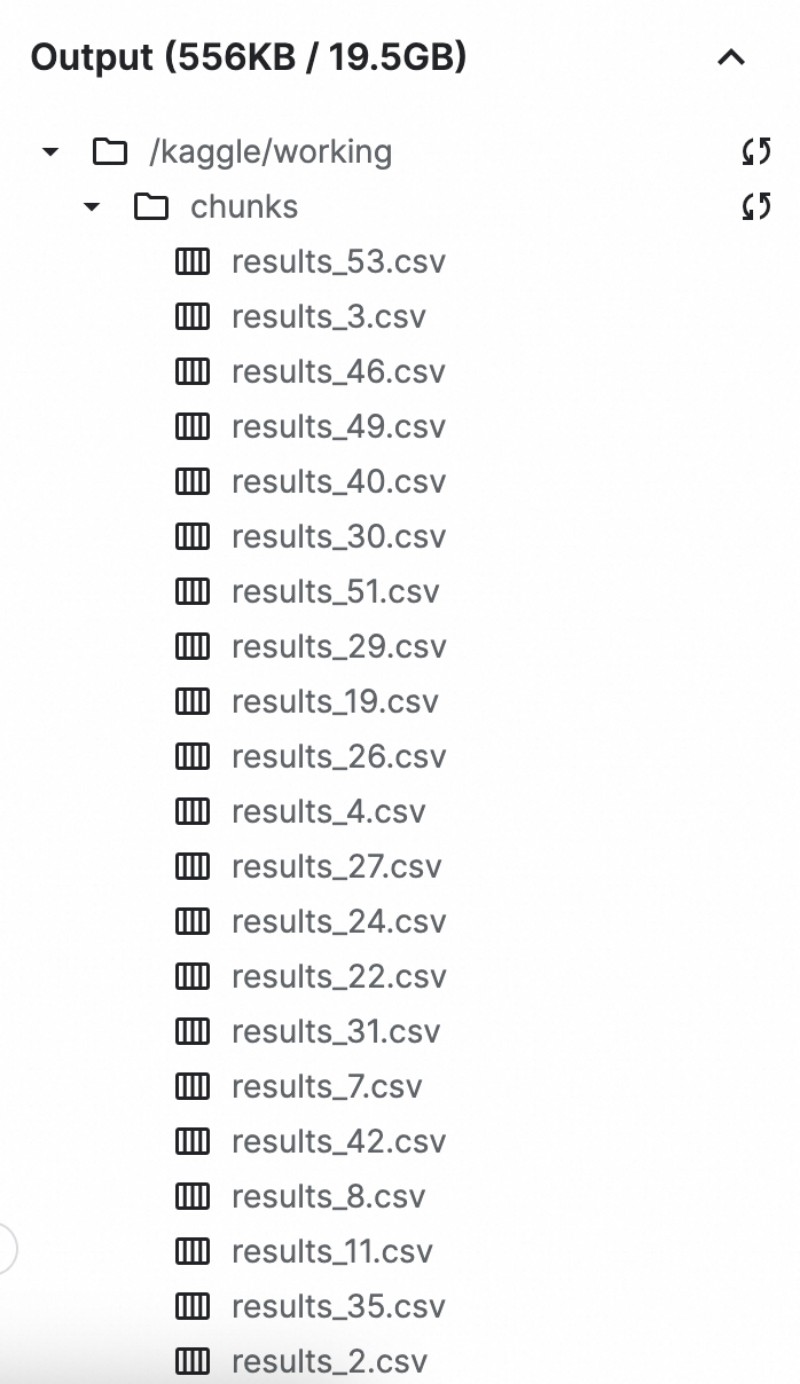
好吧,3天就3天吧。但做法得改了,要加一个分块查询、阶段性保存的功能。每查了1000行,就存到一个文件里,编上序号。下次按照序号继续查,全部查完再把这300多个文件合并成一张大表。
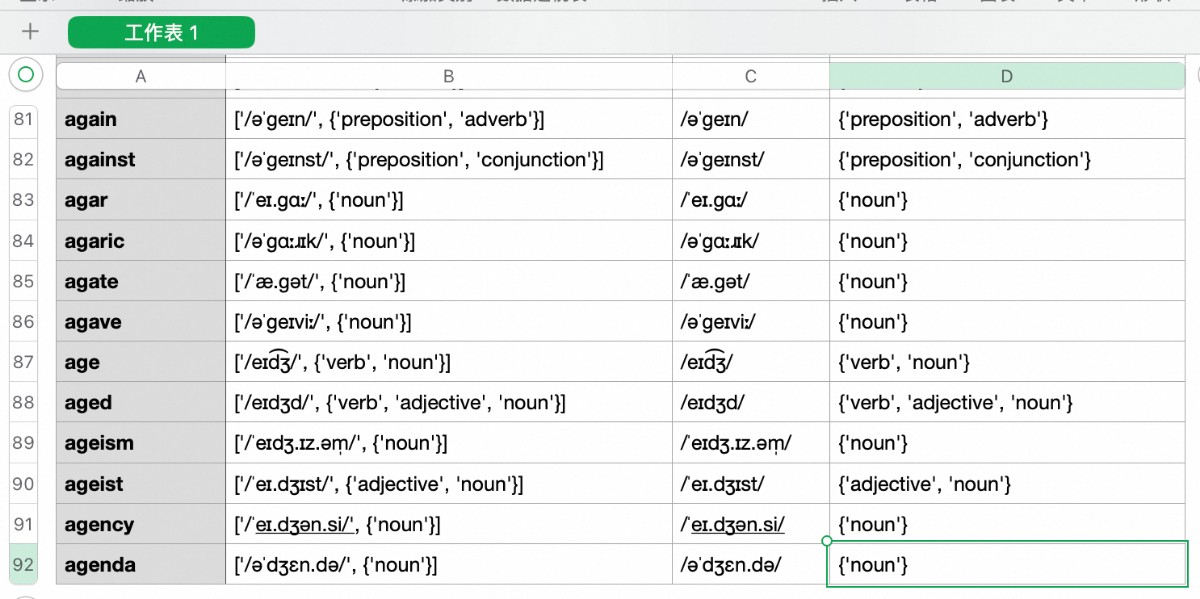
实际上,30多万个单词大部分是生僻词,在词典API里根本查不到。每1000个词里只能查出其中100个左右。上面这个文件就只有92行。
有语言学研究表示,3000个英文单词能覆盖95%的日常写作和口语,1000个单词也足以覆盖89%。另一份研究显示,成年人平均主动词汇量大约20000个,被动词汇量约40000个。这么看来,30多万的数据集大约只有1/10有用,也算是在合理范围。
数据清洗
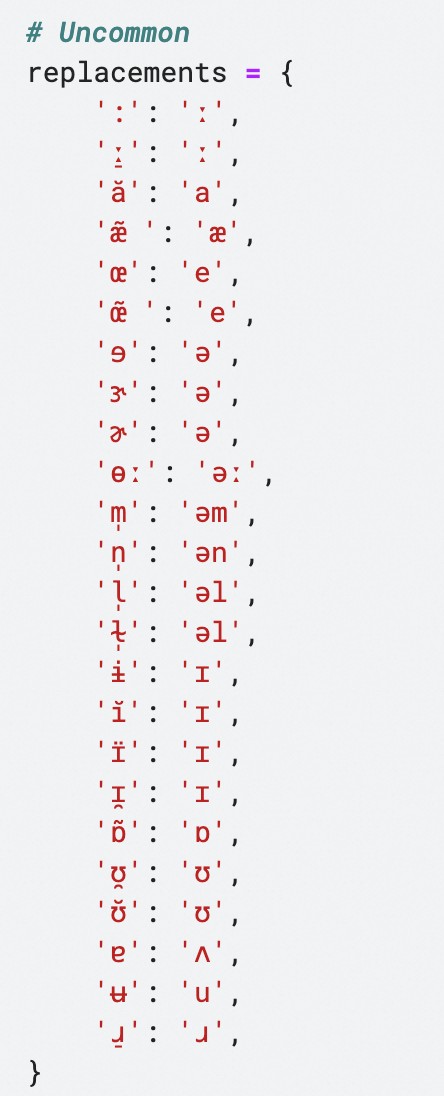
合并文件后发现,词典查出的音标符号乱七八糟,许多不常见的符号混在其中,比如 ɘ, ɝ, ɚ, ɨ, ʉ。它们是标准音的变体,在表示更精确的发音时会用到,近似等同与标准音。这些得替换掉,否则会影响音节数和后续所有分析。

除了奇怪的符号,还有许多常见音标发音相同但写法不同。比如 əu/əʊ、ai/aɪ,这些也需要合并。图里每行的意思是,把第1个音标替换成第2个音标,但中括号里的音标不动。
有的单词英音和美音有严重分歧,这里优先按美音规则替换。
这里有太多非常规写法在玩排列组合,多替换或者漏替换很容易导致音标错乱。我临时写了个检查程序,一边手动查剑桥词典确认标准的写法,一边完善我的替换规则,搞了好一会儿。
处理过后,元音符号规矩多了,以 anthropomorphic 为例:
- 处理前:
[ˌæ̃n̪θɹ̠əpəˈmɔɹ̠fɪ̈k] - 处理后:
[ˌæn̪θɹ̠əpəˈmɔːfɪk]
辅音符号对我没用,没做处理,这是个更大的坑。

后来发现,词典API有少量数据本身就不对。比如算盘(abacus)的发音,/-saɪ/,什么鬼?信息不完整。

算了一下,这种情况占全部单词的0.55%,极少。不完整的音标都列出来,看起来比较随机,没有什么共性,把它们一刀切过滤掉。现在,我实际分析的虽然不再是完整数据,而是一个样本,但样本足够大,足以反映整体,研究可以继续。
分析音标(AI)
这一步要从音标中算出单词音节数,并根据重音符号 ˈ 来判断重音落在第几个音节上。
想偷个懒,在Kaggle上部署一个AI模型,AI不是最懂语言么?让它来判断正合适。
文字类模型试了一圈,卡住了:
- 大模型跑不动: Kaggle能部署的开源模型中,Llama3 70b就可以完成任务,能稳定、准确地判断出音节数和重音位置。ChatGPT、Claude等其他家模型也都能完成,甚至GPT-3.5都可以,看来语言确实是大模型的传统强项。只是……免费版Kaggle跑不了这么大的模型。
- 小模型不给力: Kaggle免费提供的2张T4显卡可以带动7b规模的小模型,也就是Llama3 8b、Gemma 7b、Qwen2 7b这些。这些小模型无论是在Kaggle里用,还是在别的平台上用,都无法稳定地完成任务。
仔细打磨提示词,让AI一步步思考,还给了它例子:
<task>
your task is to count how many syllables there are in an English word. list them all then count. finally answer which syllable the stress falls on(tell me the number). answer **EXACTLY** in the example format.
<example>
word: analysis
phonetic transcription: /əˈnælɪsɪs/
syllables:
1. ə
2. 'næ
3. lɪ
4. sɪs
syllables count: 4
stress position: 2
final conclusion: <<<2/4>>>
<word>
analytical /æn.əˈlɪt.ə.kəl/
但小模型仍然经常出错,也许小模型就是不足以胜任这种任务吧。毕竟音标符号和日常使用的英文字母完全不一样,对AI来差不多算另一种语言了,还是小语种。
这番折腾让我明白:为什么各家开源小模型不约而同训练成了7b左右规模,就是为了刚好能跑在一张特定显卡上啊!在算力吃紧的当下,显卡才是基本计量单位。
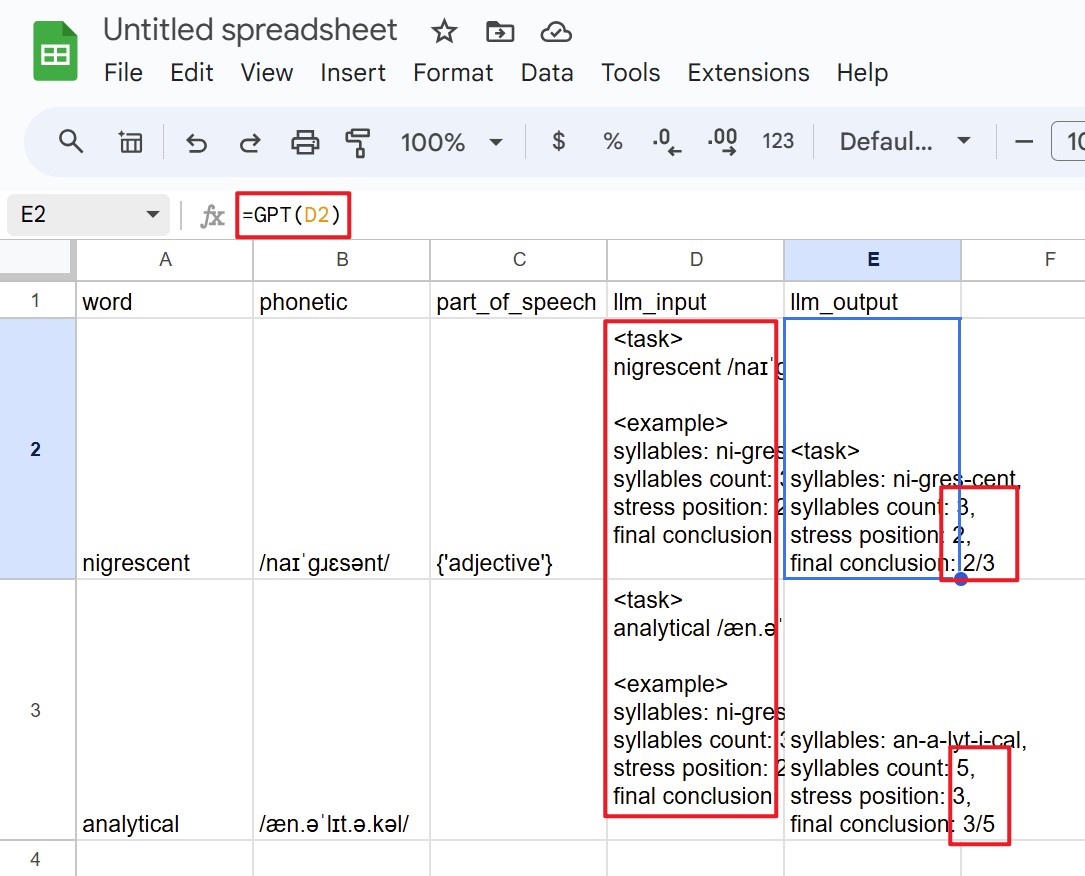
真的没法用AI了吗?又想到一个曲线救国的办法:Google Sheets+AI插件。把音标信息导到Google Sheets里,右边单元格里写上提示词,把单词和音标带进去。再右边一格使用AI插件的公式,输入提示词,得到生成结果。这个插件用的模型是GPT-3.5,能正确完成任务。然后用Excel里经典操作往下一拉,整列就都给生成了。
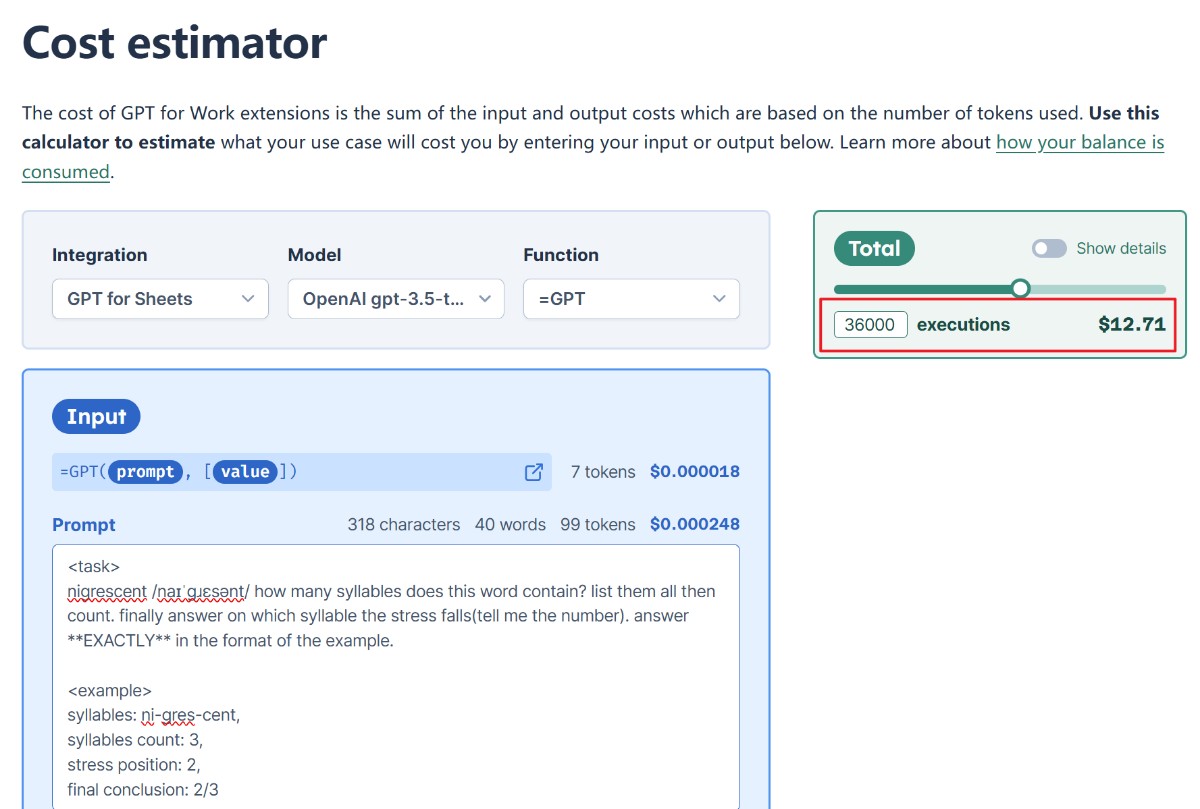
看了插件的收费标准,按数据量估算了一下,成本倒是不高,90块左右。但是不知道这几万条数据同时用AI生成,插件会不会出什么异常。如果出现问题再调试、重新生成,又是90,何时是个头,有点不太敢用。
分析音标(算法)
行吧,求AI不如求己。数音节、找重音,这事儿自己写算法也可以搞定,而且更可靠。思路如下,以 analytical /æn.əˈlɪt.ə.kəl/ 为例:
- 创建一个集合,包含所有已知的元音
ɑaæɒʌəɛeɪiɔoʊuʉɜ - 去掉音标里的斜杠、括号、空格、点等无用符号,
/æn.əˈlɪt.ə.kəl/变成ænəˈlɪtəkəl - 剩下的字符
ænəˈlɪtəkəl逐个去集合里查,是元音的就记个数,其中æ,ə,ɪ,ə,ə是元音,就得到音节数5 - 以重音符号
ˈ为分隔符把音标分段,ænəˈlɪtəkəl变成ænə和lɪtəkəl,取第1段ænə - 再用第3步的方法,数第1段的元音的个数,2个
- 这个数字+1就是重音所在的位置,重音在第3个音节上
思路出来了,具体代码就让AI写吧。 AI写这种难度的代码简直小菜一碟,没改几轮就能用了。
过程中遇到个有意思的问题,第3步数元音时,双元音怎么办?还有三重元音呢?长音呢?比如 ei 这个音,去集合里查,发现 e 是元音,i 也是元音,这样一来就算了2个音节。实际上 ei 作为双元音只算一个音节。同理,三重元音会被数成3个音节。

算法得改。元音集合分成3个,分别存放单、双、三重元音,查元音的时候要查3遍:
- 第1遍逐个字符查,比对单元音集合,双元音、三重元音会被多算。
- 第2遍两个字符查,比对双元音集合,遇到双元音,音节数就减1,抵消多算的双元音。特别需要注意的是,识别到了双元音后,下一次比对要跳过一个字符,防止把三重元音比如
aɪə算成aɪ和ɪə,这样又多减了。 - 第3遍三个字符查,比对三重元音集合,遇到三重元音,音节数再减1,抵消多算的三重元音。
修改后的算法就能准确判断音节数了。说明一下,我把长音符号 ː 也算作一个音标字符,所以 iː, ɑː 这样的长音在算法上当作双元音处理,iːə, uːə 就当三重元音处理了,不影响计算结果。
果然,做数据分析,技巧是其次,关键得懂业务啊!分析英语就得了解英语。随着对音标的深入研究,又发现了新问题:三重元音的判定非常模糊。三个元音符号连在一起时,它到底算一个三重元音,还是单元音+双元音,竟然没有共识。这熟悉的感觉……没错,这就是英语!没个准儿。
比如 fire /ˈfaɪər/ 这个词,有人认为 aɪə 是一整个音节,有人认为它是 aɪ + ə 两个。判定标准也五花八门。有说看能不能在这个位置被断行的,在一行末尾写成 fi-,再把 re 写到第2行去,fire不能这么写,所以它是三重元音。也有根据唱歌来判定的,如果唱歌的时候这个音节被唱成一个音符,那就是三重元音。这首 Simple Plan - Fire In My heart 0分57秒的时候,faɪ 和 ər 是被唱成了2个不同的音符,那么它又应该算双元音+单元音?

先不管了,这就是英语。考虑到有 oasis /oʊˈeɪsɪs/ 这样的单词存在,这都四重元音了,还有完没完?况且 oʊ 和 eɪ 明明都已经被重音符号分开了,显然是两个双元音。我决定直接无视三重元音的存在,把它们统统当作两个音节。最后,算法里的三重元音就只剩带有长音的双元音了。
得到了音节数和重音位置,我还想知道重音对应什么元音,或许也能分析出点啥来。
这个需求就略微烧脑了,一时半会儿没想明白,还是找AI讨论一下。这时候不同模型的效果高下立判,平时表现优秀的Gemini 1.5 Flash跟我兜了半天圈子,完全没有解决问题。转而求助GPT-4o,3轮对话就输出正确代码了,前后也就10分钟。又试了Claude 3.5 Sonnet,甚至一次就成功。若需要大量写代码,还是值得为优秀模型付费。当然,基本的代码理解能力还得有,看到AI的代码,要能知道它是在干什么、会不会管用、哪里可能出问题,以便让它继续调整。
它的思路是这样的,还是以 analytical /ænəˈlɪtəkəl/ 为例:
- 找到重音符号
ˈ所在的位置,从这里往后看,取lɪtəkəl这段。 - 后面的音标字符一个个看过去,不是元音就去掉,直到遇到第一个元音符号,得到
ɪtəkəl。 - 这时候开头一定是元音了,接下来取3前个字符
ɪtə,看看在不在三重元音里,不在。 - 再取前2个字符
ɪt,看看在不在双元音里,不在。 - 最后取第1个字符
ɪ,看看在不在单元音里,在,这就是重音对应的元音。
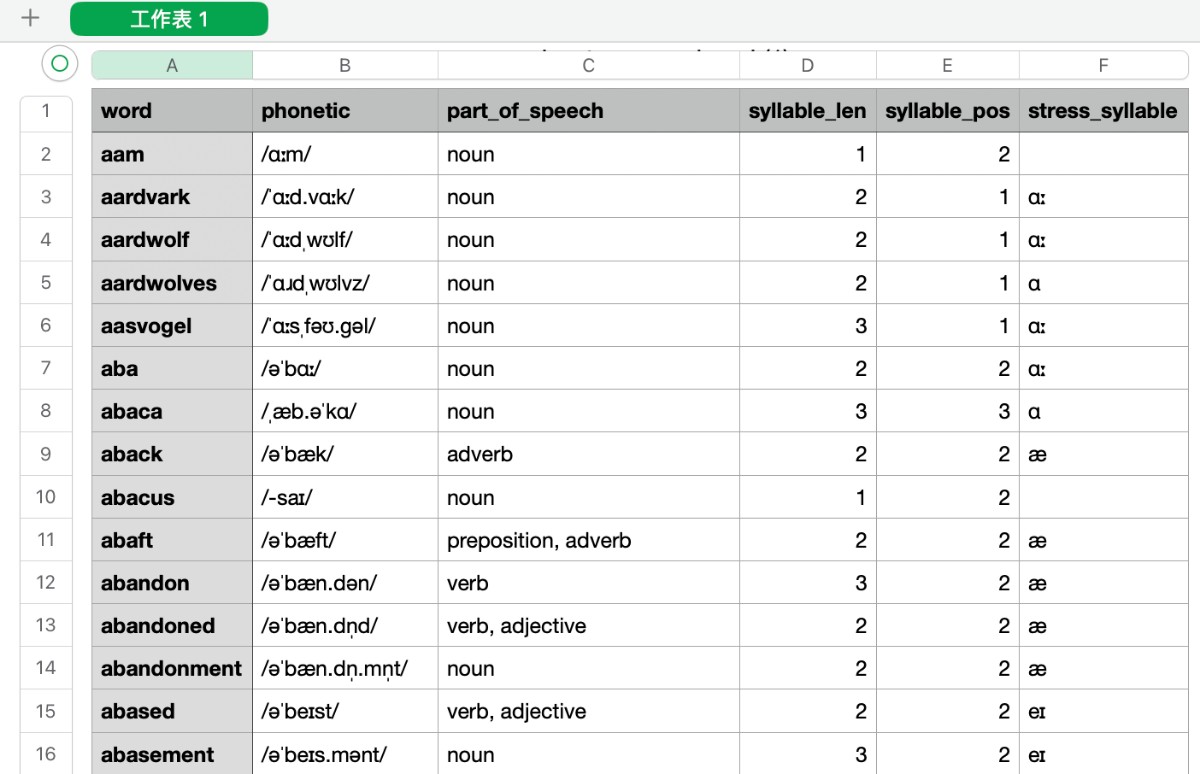
分析音标后的数据表变成这样,现在,所需的数据已经集齐了。
可视化
最爽的部分开始了,不仅因为能得出有用结论,也因为AI在这里简直指哪打哪。AI极其擅长写数据可视化Python代码,这类任务对推理能力要求不高,熟悉可视化库的语法就够了,我日常使用的Gemini 1.5 Flash这种非旗舰模型都能很好完成。Seaborn和Matplotlib这两个可视化库我没有认真学过,但借助AI,画图信手拈来。
当然,信手拈来不等于张口就来,AI什么都不知道的情况下,跟它说我要个什么什么图表,它原地摆烂给你看。我写了个Python可视化提示词,告诉它任务,告诉它数据表的结构和内容,然后就能满火力稳定输出了。
<Task>
You are a Python data visualizer. You excels at coding with data visualization libraries like Seaborn and Matplotlib. I will tell you about the structure of a Pandas dataframe and the visualization I want. First, you dive deeply into the dataframe and understand what it is all about. Then write Python code to visualize it. Just code, no explanation. Next, you check if the code meets my need. Finally, correct the code if necessary.
<Dataframe>
The dataframe(variable name is df) is {a list of common English words with their phonetic information and part-of-speech}.
Now here are the columns of the dataframe, exactly in the following order:
**word**
- datatype: str
- example: complimentary
- description: the English words
**phonetic**
- datatype: str
- example: /ˌkɒmplɪ̈ˈment(ə)ɹɪ/
- description: the phonetic transcription of the words
**part_of_speech**
- datatype: str(list like)
- example: ['adjective']
- description: how are these words used in sentences
**syllable_len**
- datatype: int
- example: 5
- description: how many syllables are there in these words
**stress_pos**
- datatype: int
- example: 3
- description: on which syllable the stress falls on, if there are more than one stress, this is the position of the first stress
**stress_syllable**
- datatype: str
- example: e
- description: the vowel of the stressed syllable
<Request>
I want to know the distribution of stress position, grouped by syllable numbers.
使用提示词,只需要修改 <Request> 部分。
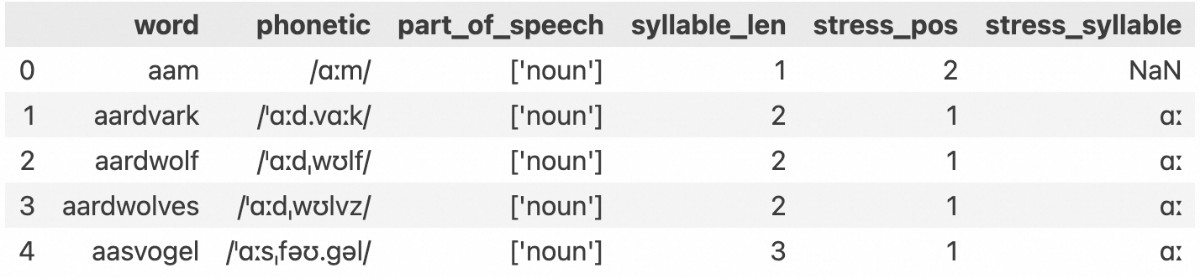
观察数据表,里面有一些词没有重音。这是因为单词比较短,音标里没有重音符号,把这些排除掉。再排除掉只有一个音节的单词,这重音即使有,位置也实在是没什么好分析的。
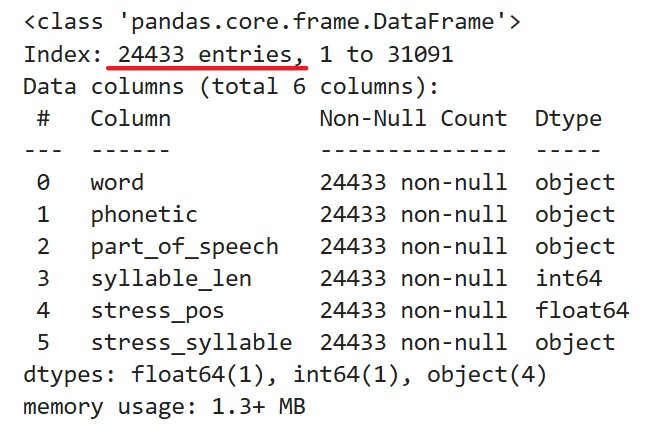
剩下24433个数据完整的单词以供分析。
音节数分析
看看这24433个单词里,音节的数量如何分布。

并不意外,音节数越少,单词数越多。一门语言的演变,当然是先把好用好记的短单词用完了,再去造更长的词。
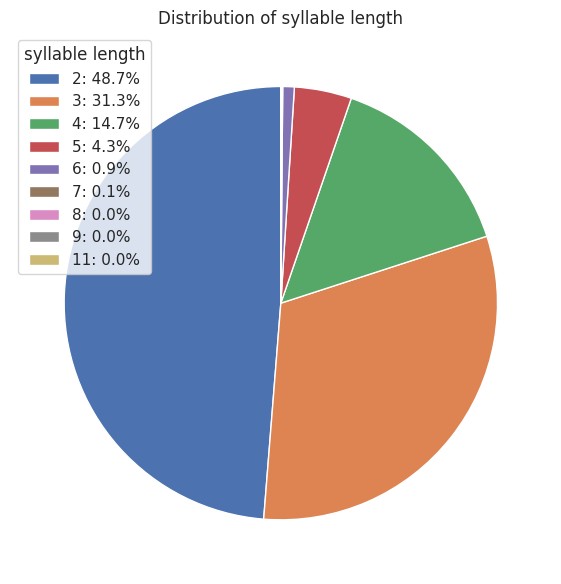
双音节单词占了48.7%,三音节单词占了31.3%。
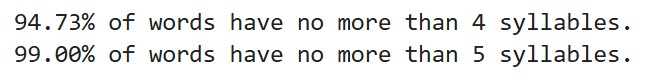
4个及以内音节的单词占总数的94.73%,5个及以内的单词占总数的99%。

音节数最多的单词竟然有11个音节。
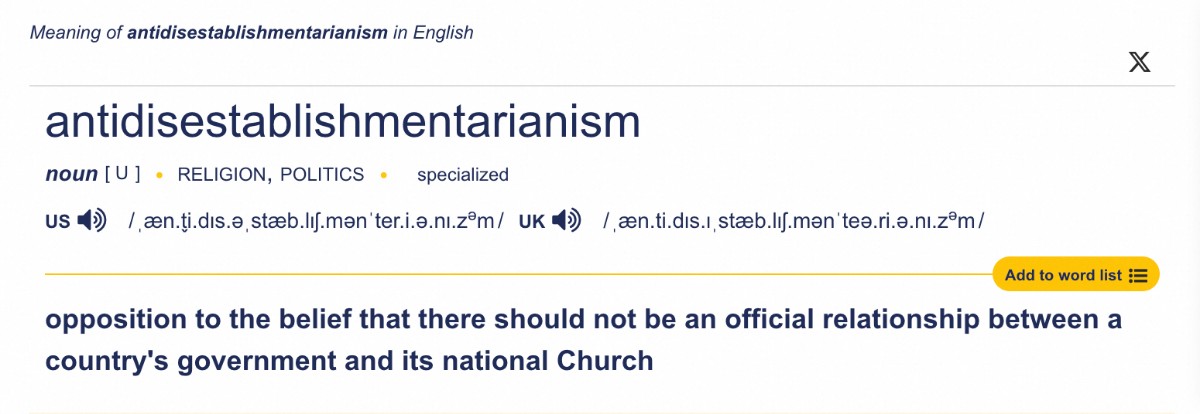
什么意思,反政教分离主义?又opposition又not,你这是双重否定套娃呀,难怪这么多音节。那我能不能在前面加non,无反政教分离主义?
音节数和重音位置的关系
先用统计学方法,计算这两组数值的相关性系数:0.67。还不错,关联度不低。
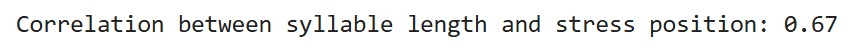
这个相关性系数的取值范围是-1到1。接近0表示两者几乎无关;接近1是正相关,一个随另一个正向变化;接近-1是负相关,一个高,另一个就低。
该系数只是统计学上的相关,是分析的第一步。排除了两者不相关,才值得继续研究下去。它并不能反映出两者有什么实际关联。
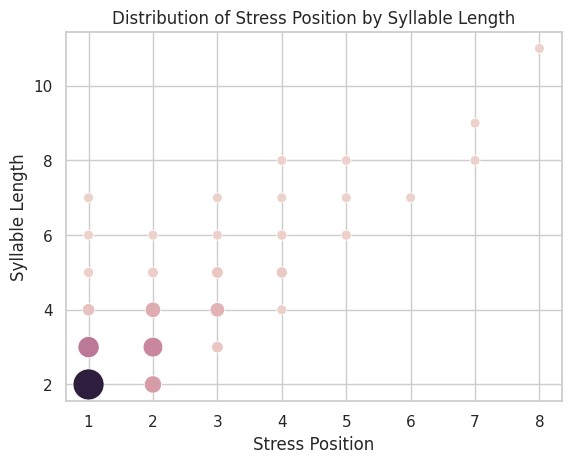
画个气泡图探索一下。纵轴音节数,横轴重音位置,气泡大小和颜色深度代表单词数量。点的分布大约沿着对角线从左下到右上一路过去,随着音节数变多,重音位置在向后移动。
气泡图(或热力图)虽然能同时展现三个维度的信息,但它们比较的是单词数量的绝对值。我更想知道的是,每一组音节数的单词重音位置分布如何。
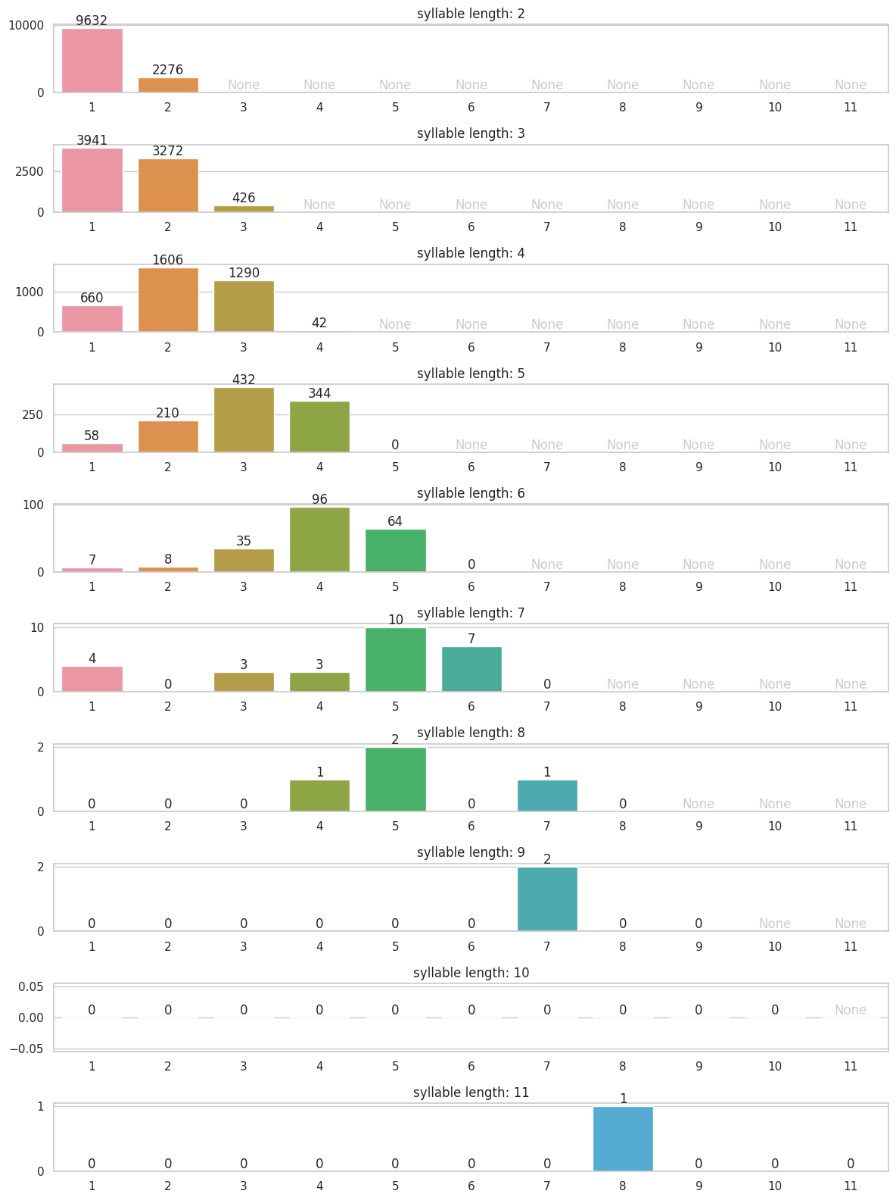
又画了一个复合柱状图,纵轴音节数,横轴重音位置。现在一目了然,重音的分布像海浪一样向右移动,而且似乎真的集中在倒数第三个音节附近。
重音音节分析

列出所有在重音位置的元音。其中一两个本不该作为元音出现在这儿,但检查了原始数据,发现词典本身数据就错了,且数量极少,对结果影响不大。
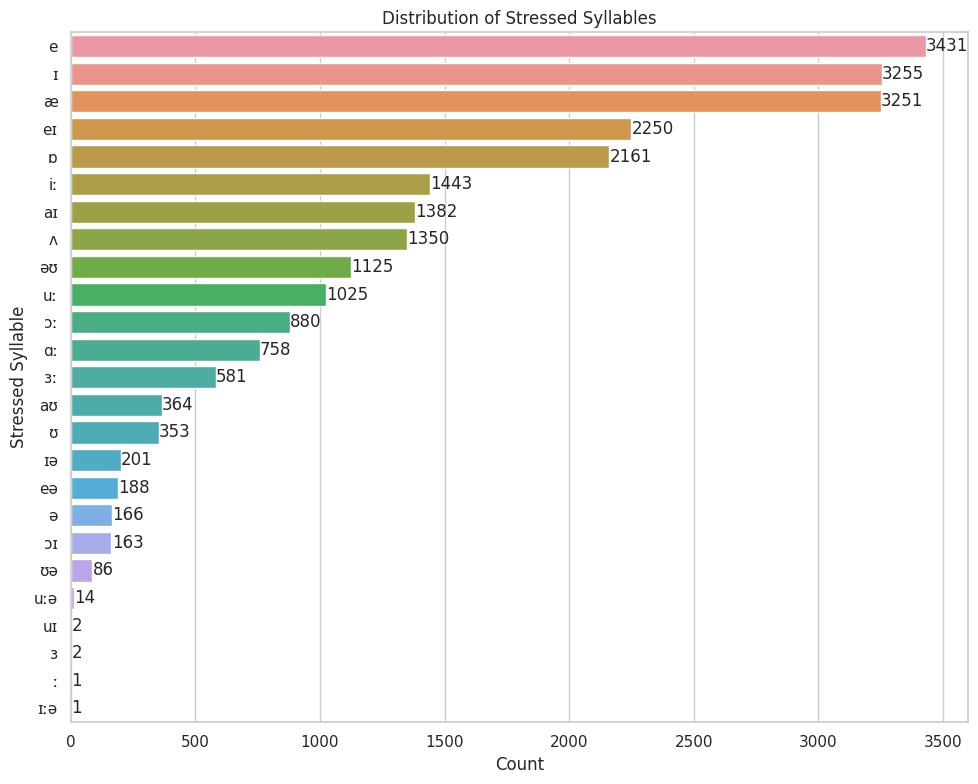
根据出现的频率做了个排行。很明显,比较响亮的 æ, e 等更容易被用作重音;而比较低沉的 ə, ʊ,用作重音效果较弱,较少在重音位置出现。
词性分析
词性和重音位置有没有关系呢?
All part of speech: ['adjective', 'adverb', 'conjunction', 'interjection', 'noun', 'numeral', 'preposition', 'pronoun', 'propernoun', 'verb']
列出数据表中所有词性。其中的 propernoun 不知道是什么玩意,这个词在词典里也没有。一查数据发现只有两个单词,而且牛头不对马嘴,怀疑是词典API数据问题,暂时忽略。
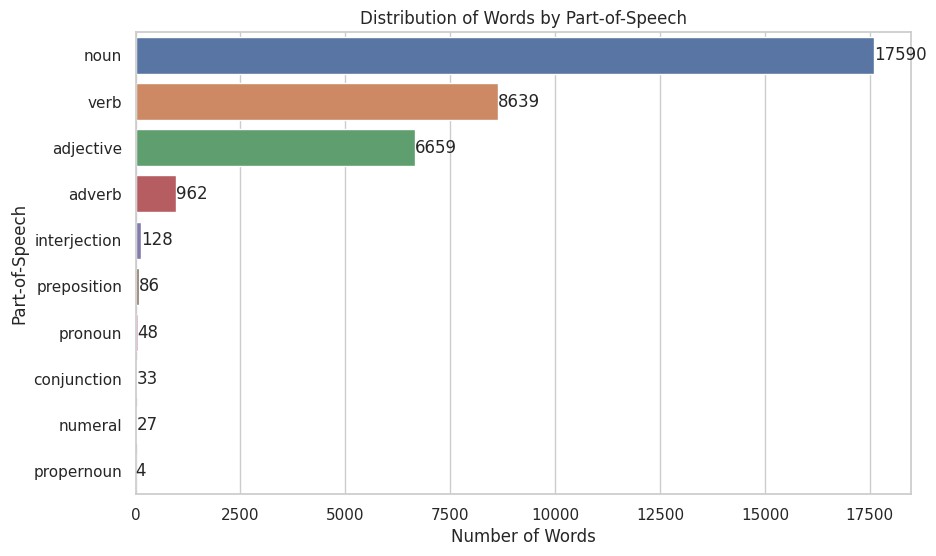
把词性做了个排行,最丰富的依次是名词、动词、形容词、副词。有一半左右是名词。
这个结果不禁让人思考语言的发展史。一门语言首先要能描绘世间万物,创造概念与之对应,名词是基础。为了描绘人和物、物和物之间的相互作用,就需要引入动词。然后需要分别对名词和动词加以修饰,补充信息,才衍生出了形容词和副词。所以单词量会按这个顺序排列,这是我的猜测。
诶,想到这里,名词和形容词、动词和副词的比例是不是应该接近呢?其实都不用计算,条形图上一目了然,名词大概是形容词的2倍多,动词则接近副词的9倍,并不成比例。
['abracadabra', 'absolutely', 'action', 'adieu', 'adios', 'affirmative', 'afternoon', 'ahem', 'alack', 'aloha', 'alright', 'amen', 'amidships', 'arrivederci', 'attaboy', 'attention', 'away', 'banzai', 'bastard', 'beauty', 'begone', 'begorra', 'behold', 'blazes', 'bollocks', 'bonjour', 'bother', 'botheration', 'brother', 'bully', 'bullseye', 'bullshit', 'caramba', 'checkmate', 'cheeses', 'condolences', 'congrats', 'congratulations', 'content', 'cooee', 'curses', 'dammit', 'ecce', 'egad', 'enchanted', 'encore', 'enough', 'eureka', 'exactly', 'farewell', 'fiddlesticks', 'flummery', 'gadzooks', 'gesundheit', 'goddamn', 'goodbye', 'gorblimey', 'gracias', 'gracious', 'greetings', 'hallelujah', 'hardly', 'havoc', 'heavens', 'heyday', 'hola', 'holla', 'honestly', 'hooray', 'hosanna', 'howdy', 'hullo', 'hurrah', 'huzzah', 'yeah', 'indeed', 'knickers', 'later', 'mercy', 'morepork', 'morning', 'namaste', 'negative', 'nonsense', 'oyez', 'okay', 'ole', 'pardon', 'peccavi', 'period', 'pity', 'pleasure', 'presto', 'prithee', 'prosit', 'quiet', 'rather', 'really', 'respect', 'result', 'roger', 'rumble', 'sayonara', 'scramble', 'selah', 'shabash', 'shazam', 'silence', 'sorry', 'standard', 'sugar', 'tally', 'tara', 'tarnation', 'tidy', 'timber', 'uncle', 'understood', 'viva', 'vivat', 'voetsek', 'warning', 'welcome', 'whammo', 'whatever', 'wilco', 'wirra', 'zowie']
出于兴趣,列出所有的感叹词,平时很少注意这个词性,所以展开来看看。发现afternoon都算啊!也对,问候语嘛。
['abaft', 'abeam', 'aboard', 'about', 'above', 'abreast', 'abroad', 'absent', 'across', 'afore', 'after', 'again', 'against', 'agin', 'along', 'alongside', 'aloof', 'alow', 'amid', 'amidst', 'among', 'amongst', 'anent', 'anti', 'around', 'asprawl', 'astraddle', 'astride', 'athwart', 'barring', 'bating', 'because', 'before', 'behind', 'beyond', 'below', 'beneath', 'beside', 'besides', 'between', 'betwixt', 'circa', 'concerning', 'considering', 'contra', 'despite', 'during', 'except', 'excepting', 'failing', 'following', 'forby', 'froward', 'given', 'including', 'inside', 'into', 'minus', 'modulo', 'nearer', 'nearest', 'onto', 'opposite', 'outwith', 'pending', 'regarding', 'regardless', 'respecting', 'rising', 'running', 'saving', 'thorough', 'throughout', 'touching', 'toward', 'towards', 'under', 'underneath', 'unlike', 'until', 'upon', 'upside', 'versus', 'wanting', 'within', 'without']
再列出所有介词,发现了一些特定模式。反复出现的词根值得注意:
- a- 表示方位或空间关系:aboard, across, amid, around
- be- 真的就是字面意思的be:before, behind, below, beside
现在为每一个词性画热力图,纵轴音节数,横轴重音位置,颜色深度表示单词量占所有该音节数单词的比例。部分词性的单词量太少,没有分析价值,只选了单词量大于总数1%的词性。
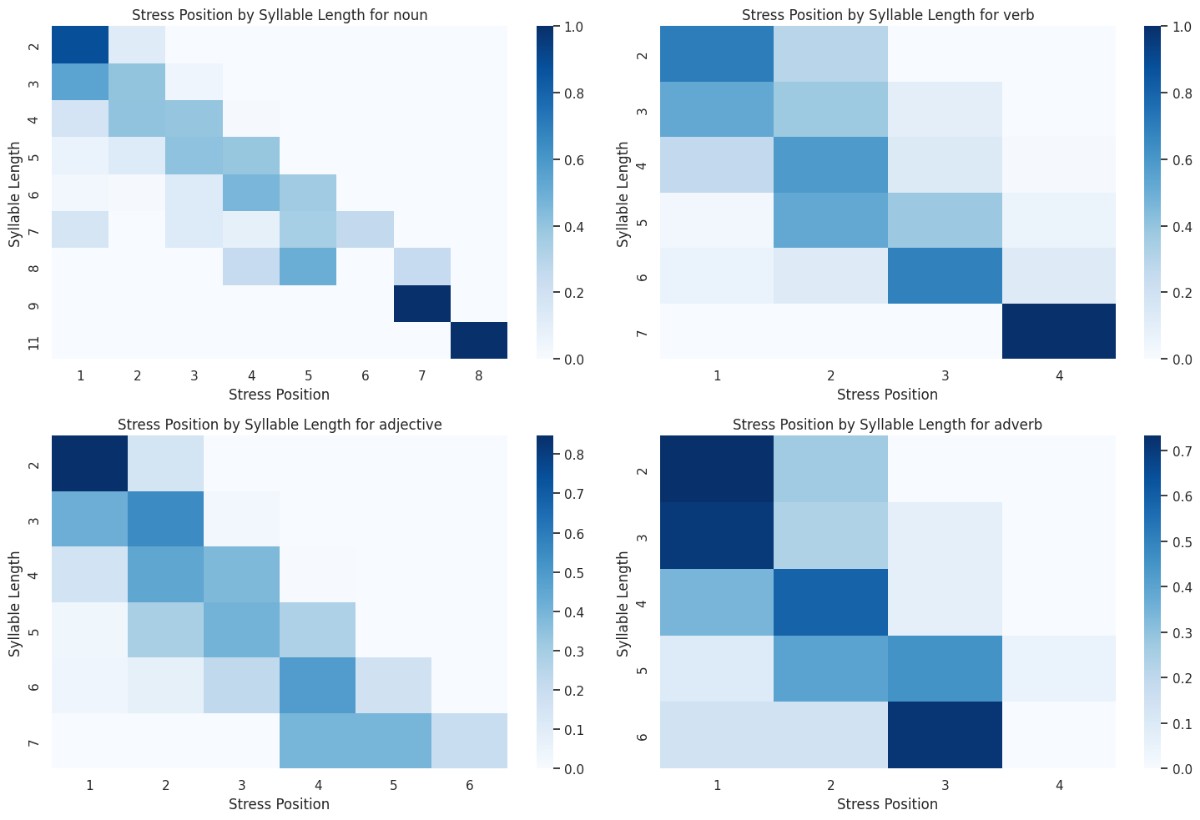
只能看出重音位置随着音节数增加而后移,不同词性之间并没有明显差别。但仔细看,其实有点区别,在长单词(5个及以上音节)的情况下,形容词重音集中在倒数第3个音节,名词重音整体偏后,动词、副词重音整体偏前。
重音位置的规律
现在,是时候验证我开篇对重音位置的猜想了。

取音节数是4和5的单词,在数据表里专门增加一列,用重音实际位置减去假象位置(倒数第3个)。这列的值可以用来分析单词重音位置是否符合我的猜想,为0则符合,为1则偏后一个音节,-1则偏前,以此类推。

符合猜想的单词,比例占43.9%。
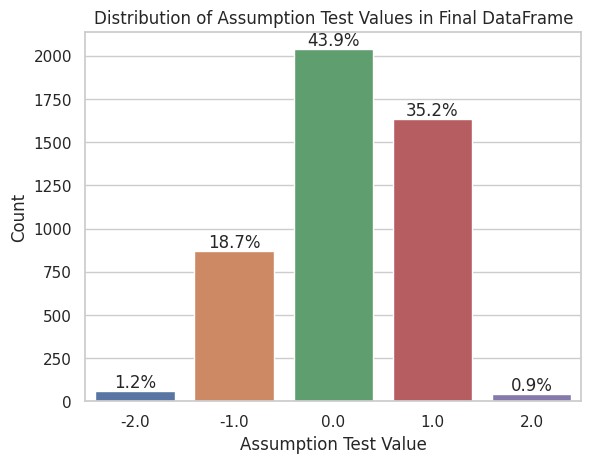
用柱状图来展示重音的偏离情况。符合规律的最多,前后偏一个音节的也有,再远的就很少很少了。这形状看着……像正态分布啊(不是,一个统计学半吊子看什么都像正态分布
到这里,我意识到我的猜测或许可以进一步推广,音节数超过5是不是也适用呢?修改数据表筛选条件,再来一遍,这次包含所有音节数大于3的单词:

符合猜想的单词,比例占43.92%。嗯,没变多少。
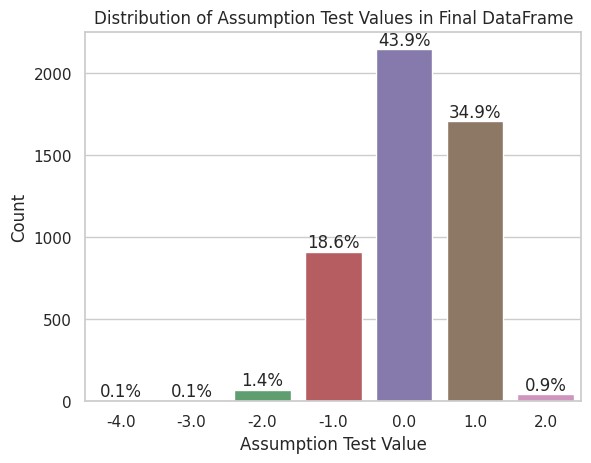
偏离依然符合猜测。重音在倒数第三个音节的单词最多,在倒数第2个音节的单词也很多,这两者加起来占到了78.84%。虽然结果和我预测的并不100%吻合,但整体规律被证实了。
结论
再总结一下。通过以上分析,关于音标和重音,有以下观察:
- 音节数越少,单词越多
- 日常几乎用不到超过5个音节的单词
- 音节最多的单词有11个音节
- 单词音节数增加,重音总体上往后移
- 较响亮的元音更容易作为重音
- 词性对重音位置影响不大
- 大多数长单词的重音落在倒数第3和倒数第2个音节上,占总数的78.84%
后记
分析5分钟,准备数据2小时。
可视化我大概只搞了半天,绝大多数时间都在准备数据,尤其从词典API查音标,断断续续跑脚本跑了两个多星期。甚至我这篇文章都写完了,词典还没查完,文中的数据结论我都用占位符占着,最终数据出来才填上的。
结论部分证实了我的猜想,还是很开心的。经过这番研究,英语单词的重音规律,我相信我永远都会记得,毕竟是自己的研究成果。
研究过程复习了Pandas的使用,掌握了分块请求阶段性保存的方法,学会了把AI整合进分析工作中,写出了一套非常有效的Python数据可视化提示词,还对英语音标有了更深入的了解。收获非常大,太值了!
在此感谢:
- 单词数据来源:这份30多万单词的列表是我整个分析的基础。
- 免费词典API:提供了低成本获取这些单词音标的途径。
- Gemini 1.5 Flash:帮我完成了一半左右数据准备工作和全部的数据可视化工作。
- GPT-4o:帮我准确找出了重音位置的元音。
整个分析过程及相关代码,已经开源分享在Kaggle上了,看完故事如果还对代码感兴趣,请前往:
https://www.kaggle.com/code/victorcheng42/stress-distribution-of-english-words
中间过程产生的带有音标、音节数、重音位置的数据集也公开了。如有其他分析需要,可以看看能不能帮到你:
https://www.kaggle.com/datasets/victorcheng42/english-words-with-stress-position-analyzed